论文:Deep Semantic Text Hashing with Weak Supervision,SIGIR,2018
论文提出一种弱监督学习方法。采用bm25对相似文档进行排序,提取数据中的弱监督信号。先训练一个可以得到整个文档的语义向量表示的模型,然后根据语义向量,运用一些规则(设置阈值)将对应维度变成0或1。
- 通过使用无监督排序来逼近真实的文档空间,从而弥补了标记数据的不足。
- 设计了两个深度生成模型来利用文档的内容和估计的邻域来学习语义哈希函数。(NbrReg和NbrReg+doc)
两个语义向量表示模型(NbrReg和NbrReg+doc)区别在于是否利用了近邻文档信息。每个模型包含两个部分:encoder、decoder。
该方法步骤包括三个部分:Document Space Estimation —> NbrReg(NbrReg+doc) —> Binarization
- Document Space Estimation:得到整个文档数据的空间分布情况
在有标签信息的情况下,可以得到真实文档空间分布。没有标签信息的时候,利用bm25为每个文档 d 检索出一组与之最相似的近邻文档NN(d)。论文假设:近邻文档中大多数与文档 d 具有相同标签,因此任何文档的二进制哈希值在相近的向量空间模型中应该更加近似。
- NbrReg:语义向量模型
文档语义向量 s ,满足标准正态分布 N(0,1)
wi ∈ d ,概率 PA(wi|s) ; ŵj ∈ NN(d) ,概率PB(ŵj|s)
定义联合概率: P(d) = ∏iPA(wi|s) ,P(NN(d)) = ∏jPB(ŵj|s)
目标函数:最大化P(d, NN(d)) = P(d)P(NN(d))
$$
logP(d,NN(d)) = log\int_{s}P(d|s)P(NN(d)|s)P(s)ds\\\geq
E_{Q(s|·)}[logP(dd|s)] + E_{Q(s|·)}[logP(NN(d)|s)]-D_{KL}(Q(s|·)||P(s))
$$ 其中 Q(d|·)
表示从数据中学到的近似后验概率分布;·
符号表示输入随机变量的占位符;DKL
表示KL散度;
Decoder Function $$ P(d) = \prod_{i}P_A(w_i|s)=\prod_{i}\frac{exp(s^TAe_i)}{exp(\sum_{j}s^TAe_j)} $$ ej 表示一个词袋向量,矩阵A将语义向量s映射到词编码空间。P(NN(d)) 与上面类似,只是映射矩阵用B表示。
Encoder Function
定义 Q(s|·) 为文档d参数化的正态分布:Q(s|·) = N(s, f(d)) 。f(·) 函数将d表示为均值为μ 标准差为σ 正态分布的向量。 为了表征两个参数,定义f = < fμ, fσ> ,相当于定义了两个前馈神经网络: $$ f_{\mu}(d) = W_{\mu}·h(d)+b_{\mu} \\f_{\sigma}(d) = W_{\sigma}·h(d)+b_{\sigma}\\h(d) = relu(W_2·relu(W_1·d+b_1)+b_2) $$
语义向量s从Q中采样: s ∼ Q(s|d) = N(s; μ = fμ(d), σ = fσ(d))
- Utilize Neighbor Documents:(NbrReg+Doc)
论文中提到相邻文档使用的一组单词可以表示该区域所有文档的主题,但是来自相邻文档的额外的词可能会引入噪声,混淆模型。为了削减噪声带来的影响,引入了一层隐藏层,用该层向量来表示近邻文档,使用一个平均池化层得到 近邻文档的中心表示。只有编码器部分有所不同,其他与NbrReg一致。 $$ Z^{NN} = relu(W_2^{NN}·relu(W_1^{NN}·NN(d)+b_1^{NN})+b_2)\\h_{NN}(NN(d)) = mean(Z^{NN})\\f_{\mu}(d,NN(d)) = W_{\mu}·(h(d)+h_{NN}(NN(d)))+b_{\mu} $$
- Binarization
根据编码器 Q(s|·) 为文档d生成一个连续的语义向量。论文中使用编码器输出的正态分布的均值来表示语义向量 $\overline s = E[Q(s|·)]$,然后使用中值法生成二进制编码。若大于该阈值就令该位为1,否者为0.
思考
论文并没有显示道德直接学习二进制表示,而是通过训练一个语义模型,假设语义相近文档对应二进制表示应该相近,然后通过语义向量进一步转化为二进制哈希值。值得一提的是语义向量是服从正太分布的,一方面便于训练,另一方面也可以给模型提供很好的可解释性,所有文档可以映射到正态分布的语义空间,语义相近的向量具有相近的分布值(论文假设语义向量服从正太分布,并用其均值表示),这也确保了二值化的时候语义相近的文档在映射为二进制哈希值后也保持距离相近。
开源代码
github上找到两处开源代码,一个是作者的低调开源,一个是路人甲的好心复现。
作者开源:https://github.com/unsuthee/SemanticHashingWeakSupervision
复现代码:https://github.com/yfy-/nbrreg
作者开源的代码,一言难尽,虽然很贴心的把对比模型也复现了出来,但是数据没给,如何用bm25算法处理的过程都给省去了。于是找到了一个好心人提供了nbrreg模型的复现,而且给了一份数据,以及对数据进行处理的代码。但是模型训练没有考虑到用gpu的情况。所以下面主要对复现代码进行分析。
数据处理
提供的数据是20newsgroups数据集,20ng-all-stemmed.txt:18820行,20个类别
1 | alt.atheism alt atheism faq atheist resourc archiv name atheism resourc alt atheism... |
格式为:label w1 w2 w3…,一行为一条数据,由标签和对应文档组成,文档由一个空格分开的词组成。
数据处理代码为:prepare_data.py
- 输入:20ng-all-stemmed.txt中的文本
- 输出:train_docs、cv_docs、test_docs、train_cats、cv_cats、test_cats、train_knn
- train_docs、cv_docs、test_docs:分别为训练集、验证集、测试集,维度为vocab_size。
- train_cats、cv_cats、test_cats:对应标签,one-hot向量,维度为20。
- train_knn:train_docs中每条数据的近邻文档的索引。
这部分代码主要是得到用于模型输入的数据,即将文本数据用数值表示。这里将每个文档用bm25权重值表示。BM25是信息索引领域用来计算query与文档相似度得分的经典算法。论文中使用bm25检索近邻文档,作为训练的弱监督信号。
BM25的一般公式: $$ Score(Q,d) = \sum_{i=1}^{n}W_i*R(q_i,d) $$ Q表示一个query,qi 表示Q中的单词,d表示某个搜索文档。Wi 表示单词权重,用idf 表示: $$ idf(q_i) = log\frac{N-df_i+0.5}{df_i+0.5} $$ dfi 为包含了qi 的文档个数。依据IDF的作用,对于某个 qi,包含 qi的文档数越多,说明qi重要性越小,或者区分度越低,IDF越小,因此IDF可以用来刻画qi与文档的相似性。
R(qi, d) 表示为: $$ R(q_i,d) = \frac{(k_1+1)·f(q_i,d)}{f(q_i,d)+k_1·(1-b+b·\frac{|d|}{avgdL})} $$ f(qi, d) 表示qi在文档 d 中的词频,|d| 表示文档 d的长度,avgdL是语料库全部文档的平均长度。k1 和 b 为经验参数,一般的k1 ∈ [1.2, 2.0], b = 0.75
假设一共有 n 个文档,按照该公式计算最终一个文档 d 会得到 n 个得分。但是代码中计算的是Score(d, d) ,而且没有求和操作。所以一个文档 d 会由一个vocab_size维度大小的向量表示。按照论文要求,会根据 n 个得分进行降序排列,选 k 个作为文档 d 的近邻文档NN(d) 。复现的代码中则是根据上述向量计算余弦相似度然后选取近邻文档的。
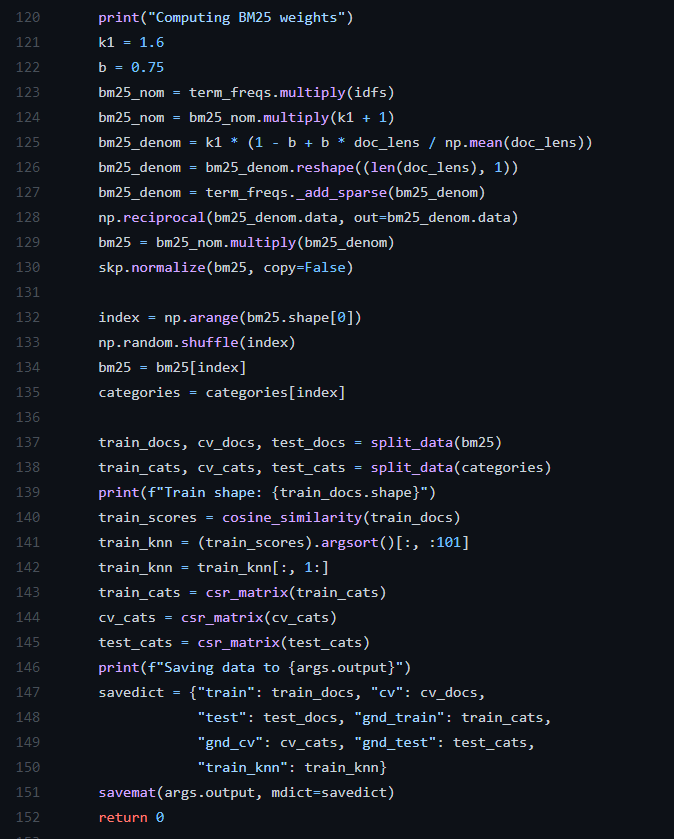
其中term_freq 对应词频f(qi, d) 的n × vocab_size 大小的矩阵,cosin_similarity(train_docs) 计算文档与文档之间的余弦相似度得分。代码中近邻文档选取了100个 。
计算idf值代码:
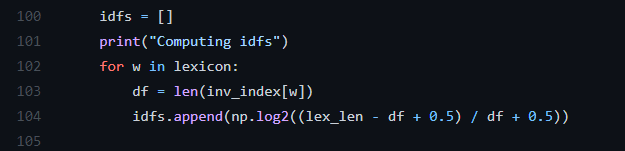
这一处分母应该是(df + 0.5) 。少了一个括号!!!
模型训练测试代码都在一个文件里:nbrreg.py
1 | class NbrReg(torch.nn.Module): |
模型部分按照论文中的描述,使前馈神经网络就可以实现。值得一提的是 qdist 应该才是文中对应的服从正态分布的语义向量 s。但在生成二进制哈希值时,取的是编码器输出的均值。
训练代码:
1 | def train(train_docs, train_cats, train_knn, cv_docs, cv_cats, bitsize=32, |
没有使用GPU!!!kl_loss = tdist.kl_divergence(qdist, norm)
计算KL散度。norm 为标准正态分布。
测试代码:
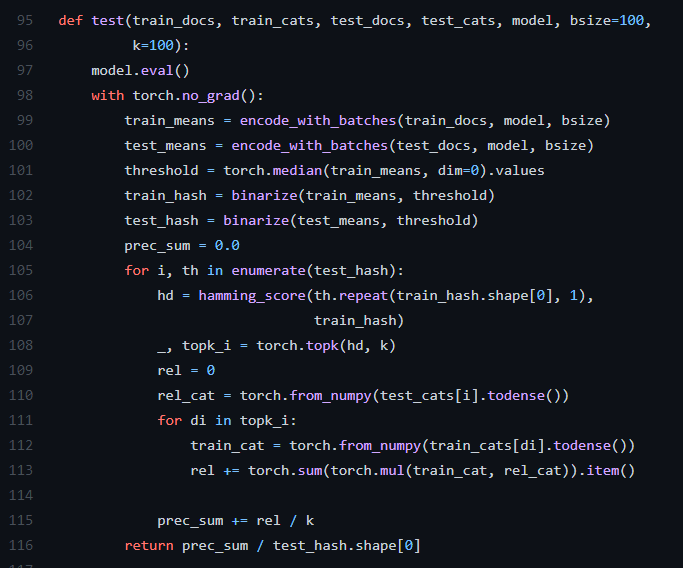
这里 k=100,表示近邻文档取100,这里为test进行二进制哈希映射后,根据汉明距离选取距离最近的k个,然后统计这k个中与test标签相同的数目,相同数目越大表示即准确率越大,模型效果越好。
注意事项
在使用该代码时,需要对数据处理成
20ng-all-stemmed.txt文件里的格式。然后用prepare_data.py
处理生成对应的.mat
文件。将源句子与其复述句标记为相同标签。
- 固定种子,保证结果可复现。(基本操作)
- 计算 idf 时,把代码里的小错误纠正了。(分母加了括号)
- 去掉余弦相似度计算,在已知标签的情况下,近邻文档直接从标签相同的文档中取k个。(bm25已经名存实亡,文档向量用TF-IDF值效果差不多)
- k值调整,代码中默认100,论文中说为50的时候准确率不在提升,真的是谜之操作。要根据实际情况而定,看每个源句子对应的复述句子的数量,如果k设置过大,则会引入大量噪声。
test函数中的k要与数据处理中的k保持一致,或者小于。(至关重要,不然准确率上不去,而且低到百分之零点几,k=2时,平均准确率有0.43+) - 改成了可以使用gpu训练的代码。(至少可以快七倍)
- 解耦,把训练、测试、模型、数据处理分开。
开始小数据训练,准确率很低。后面就增加数据,准确率依旧那样。开始以为bm25权重计算错误,然后发现代码中
idf
的计算与公式有出入。然后改正了,接着训练,效果还是不好。然后将两份代码对比,发现作者开源的代码里对KL散度值给了一个权重。然后又加权重值,效果还是那样。训练时开始调整knn-size的值,效果好了一点点,但还是很低很低。然后尝试解耦代码,把各个模块代码重新整理,然后发现test
函数里有个参数
k,默认值100,训练一轮后测试模型时,并没有设置该参数,还是默认100。train_knn
的 k 值过大,则会引入噪声,test 中 k
值过大,造成分母过大,准确率很难上去。