Translation-Based Steganography
基于翻译的隐写术
abstract
这篇论文研究了用隐写术在自然语言文档自动翻译产生的噪音(“noise”)中隐藏信息的可能性。由于自然语言固有的冗余性为翻译的变化创造了足够的空间,因此机器翻译非常适合隐写。此外,因为在自动文本翻译中经常出现错误,信息隐藏机制插入的额外错误就很难检测出来,看起来就像是翻译过程中产生的正常噪音的一部分。正因如此,我们是很难确定翻译中的不准确是由隐写术的使用还是由翻译软件的缺陷造成的。
introduction
本文提出了一种用于自然语言文本中的隐蔽消息传输的新协议,为此我们有一个概念验证(proof-of-concept )实现。关键点就是将信息隐藏在自然语言翻译中经常出现的噪音中。在一对自然语言之间翻译[non-trivial]文本时,通常有许多可能的翻译结果。【大概意思应该是在不改变原文意思的情况下,翻译的结果是多种多样的】。选择这些翻译结果之一就可用于对信息进行编码。一个 adversary 要想检测出其中隐藏的信息,就必须明白包含隐藏信息的翻译是不可能由普通翻译生成的。由于翻译过程中本就夹杂一些噪声,这使得检测隐藏信息是十分困难的。例如,由于同义词的存在,在对原文进行翻译的过程中,使用同义词进行替换。随着翻译结果的增加,也增加了信息隐藏的可能性。
本文评估了使用自动机器翻译 (MT) 的自然语言翻译中隐蔽消息传输的潜在性。为了描述在机器翻译中的哪种变化是合理的,我们研究了各种 MT 系统产生的不同类型的错误。在机器翻译中观察到的一些变化对于人工翻译也显然是合理的。除了让 adversary 难以检测到隐藏信息的存在之外,基于翻译的隐写术也更容易使用。与之前的基于文本、图像和声音的隐写系统不一样,基于翻译的隐写,其 cover 是不需要保密的【the cover does not have to be secret.】。在基于翻译的隐写术中,源语言的原始文本可以是公开的,可以从公共资源中获取,并与译文一起,在adversary的视线范围内,在两方之间进行交换。在传统的图像隐写术中,经常出现的问题是,随后隐藏消息的源图像必须由发送者保密并且只使用一次(否则“diff”攻击将揭示隐藏消息的存在)。这增加了用户为每条消息创建新的秘密封面(secret cover)【周杰伦的专辑《不能说的秘密》?!滑稽脸.jpg】的负担。
In translation-based steganography, the original text in the source language can be publically known, obtained from public sources, and, together with the translation, exchanged between the two parties in plain sight of the adversary. In traditional image steganography, the problem often occurs that the source image in which the message is subsequently hidden must be kept secret by the sender and used only once (as otherwise a “diff” attack would reveal the presence of a hidden message). This burdens the user with creating a new, secret cover for each message.
基于翻译的隐写术没有这个缺点,因为对手无法对翻译应用差异分析来检测隐藏的消息。对手可能会生成原始消息的翻译,但无论使用隐写术,翻译可能会有所不同,使得差异分析无法检测隐藏的消息。
为了证明这一点,我们实现了一个隐写编码器和解码器。该系统通过以类似于在现有 MT 系统中观察到的变化和错误的方式更改机器翻译来隐藏消息。我们的网页上提供了原型的交互式版本。
在本文的其余结构如下。首先,第 2 节回顾了相关工作。在第 3 节中,描述了隐写交换的基本协议。在第 4 节中,我们给出了现有机器翻译系统中产生的错误的特征。第 5 节概述了实现和一些实验结果。在第 6 节中,我们讨论了基本协议的变体,以及各种攻击和可能的防御。
Related Work
Protocol
本文的基本隐写协议工作如下。发件人首先需要获得源语言的封面(cover)。封面不必是保密的(secret),可以从公共来源获得 , 例如,新闻网站。然后发送者使用隐写编码器将源文本中的句子翻译成目标语言。隐写编码器本质上为每个句子创建多个翻译,并选择其中之一来对隐藏消息中的位进行编码。然后将翻译后的文本连同足以获得源文本的信息一起发送给接收者。这可以是源文本本身或对源的引用。然后接收者还使用相同的隐写编码器配置执行源文本的翻译。通过比较结果句子,接收者重建隐藏消息的比特流。图 1 说明了基本协议。
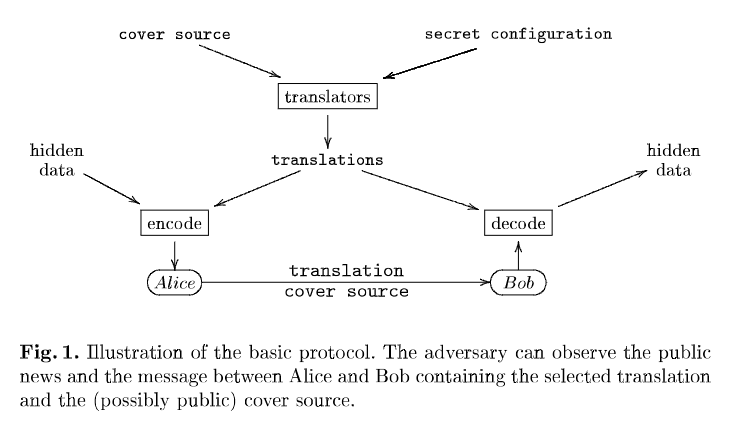
Producing translations
获取源文本后,发送方和接收方的第一步是使用相同的算法生成源文本的多个翻译。此步骤的目标是确定性地生成源文本的多个不同翻译。实现这一目标的最简单方法是在源文本中的每个句子上应用所有可用 MT 系统的(子集)。如果各方可以完全访问统计 MT 系统的代码,他们可以通过使用不同的语料库训练,从同一代码库生成多个 MT 系统。
除了使用多个翻译系统生成不同的句子外,还可以对结果翻译应用后处理以获得额外的变化。这种后处理包括模拟任何(MT)翻译中固有噪声的转换。例如,后处理器可以插入常见的翻译错误(如第 4 节所述)。
由于不同引擎之间的翻译质量不同,并且还取决于应用了哪些后处理器来处理结果,因此翻译系统使用启发式方法为每个翻译分配一个概率,描述其与其他翻译相比的相对质量。启发式可以基于生成器的经验和基于语言模型对句子质量进行排名的算法 。用于生成翻译及其排名的特定翻译引擎、训练语料库和后处理操作集是想要进行秘密通信的两方密钥共享的一部分。
Selecting a translation
选择翻译以对隐藏消息进行编码时,编码器首先使用生成器算法分配的概率构建可用转换的霍夫曼树。然后算法选择与要编码的位序列对应的句子。
使用霍夫曼树根据翻译质量估计选择句子可确保较少选择翻译质量较低的句子。此外,所选翻译的质量越低,传输的比特数就越高。
这减少了所需的封面文本总量,从而减少了对手可以分析的文本量。编码器可以使用相对翻译质量的下限来排除估计翻译质量低于某个阈值的句子,在这种情况下,该阈值成为发送者和接收者之间共享秘密的一部分。
Keeping the source text secret
所提出的方案可以适用于需要对源文本保密的水印。这可以按如下方式实现。编码器计算每个翻译句子的(加密)哈希。然后它选择一个句子,使得翻译句子的散列的最后一位对应于要传输的隐藏消息中的下一位。 然后解码器只计算接收到的句子的散列码并连接相应的最低位获取隐藏信息。
该方案假设句子足够长,几乎总是有足够的变化来获得具有所需最低位的散列。每当没有一个句子产生可接受的哈希码时,就必须使用纠错码来纠正错误。使用这种变化会降低编码所能达到的比特率。更多细节可以在我们的技术报告中找到。
Lost in Translation
现代 MT 系统会在翻译中产生许多常见错误。本节描述了其中一些错误的特征。虽然我们描述的错误不是可能错误的完整列表,但它们代表了我们在示例翻译中经常观察到的错误类型。翻译错误的扩展特征可以在我们的技术报告中找到(由于篇幅限制,此处省略)。这些错误中的大多数是由于当代 MT 系统对统计和句法文本分析的依赖造成的,导致缺乏语义和上下文意识。这会产生一系列错误类型,我们可以使用它们来合理地改变文本,从而产生进一步的标记可能性。
Functional Words
一类经常发生但不破坏意义的错误是功能词翻译不正确,如冠词、代词和介词。因为这些功能词通常与句子中的另一个词或短语有很强的关联,复杂的结构似乎经常会导致这些词的翻译错误。此外,不同的语言对这些词的处理方式非常不同,因此在使用未考虑这些差异的引擎时会导致翻译错误。
例如,许多使用冠词的语言并不在所有名词前使用它们。这在从文章规则不同的语言翻译时会导致问题。例如,法语句子“La vie est paralysee.”在英语中翻译为“Life is paralyzed.”。然而,翻译引擎可以预见地将其翻译为“The life is paralyzed.”;“life in general”意义上的“life”并没有用出现在一篇英文文章中。这与许多不可数名词如“水”和 “钱”一样,而导致类似的错误。
通常,介词的正确选择完全取决于句子的上下文。例如,法语中的 J′habite à 100 mètres de lui在英语中的意思是“我住在离他100米的地方”。然而,[20] 将其翻译为“我与他一起生活 100 米”,而 [71]将其翻译为“在他的 100 米处生活”。两者都使用“à”(“with/in”)的不同翻译这完全不适合上下文。
Blatant Word Choice Errors
不太常见的是,在翻译中选择完全不相关的单词或短语。例如,I’m staying home和I am staying home都被[20]翻译成德语为Ich bleibe Haupt(I’m staying head)而不是Ich bleibe zu Hause。这些不同于语义错误,反映了实际引擎或其字典中的某种缺陷,明显影响了翻译质量。
Additional Errors
遇到了其他几种有趣的错误类型,由于篇幅原因,我们将只简要介绍这些错误类型。
- 基本语法错误导致翻译如It do not work
- 逐字翻译,尤其是惯用语的翻译,会产生诸如The pencils are at me.这样的结构
- 源词典中没有的单词只是不翻译
- 语言之间反身结构的不正确映射会导致反身冠词被错误地插入目标翻译中(例如,Ich kamme mich变成了I comb myself)。
Translations between Typologically Dissimilar Languages
类型学上相距遥远的语言是指形式结构彼此完全不同的语言。这些结构差异体现在许多领域(例如句法(短语和句子结构)、语义(含义结构)和形态(词结构))。毫不奇怪,由于这些差异,在类型上相距遥远的语言(中文和英文、英文和阿拉伯文等)之间的翻译经常很糟糕,以至于不连贯或不可读。我们在这项工作中没有考虑这些语言,因为翻译质量通常很差,结果翻译的交换可能是难以置信的。
Implementation
本节描述了实现的一些方面,重点介绍了用于获得生成的翻译变化的不同技术。
Translation Engines
当前实现使用 Internet 上可用的不同翻译服务来获得初始翻译。当前的实现支持三种不同的服务,我们计划在未来添加更多服务。添加新服务只需要编写一个函数,将给定的句子从源语言翻译成目标语言。应使用可用 MT 服务的哪个子集由用户决定,但必须至少选择一个引擎。
选择多个不同翻译引擎的一个可能问题是它们可能具有不同的错误特征(例如,一个引擎可能无法翻译带有缩写的单词)。知道特定机器翻译系统存在此类问题的对手可能会发现所有句子中有一半存在与这些特征匹配的错误。由于普通用户不太可能在不同的翻译引擎之间交替,这将揭示隐藏消息的存在。
更好的选择是使用相同的机器翻译软件,但使用不同的语料库对其进行训练。特定语料库成为隐写编码器使用的密钥的一部分; Victor Raskin 和 Umut Topkara 之前在另一个上下文([2] 的上下文)中讨论了这种使用语料库作为关键字的情况。因此,对手无法再检测到不同机器翻译算法导致的差异。这种方法的一个问题是获得好的语料库很昂贵。此外,划分单个语料库以生成多个较小的语料库将导致更糟糕的翻译,这可能再次导致可疑文本。也就是说,完全控制翻译引擎还可以允许翻译算法本身的微小变化。例如,GIZA++系统提供了多种计算翻译的算法[9]。这些算法的主要区别在于如何生成翻译“候选结果”。更改这些选项也有助于生成多个翻译。
从翻译引擎获得一个或多个翻译后,该工具会使用各种后处理算法生成其他变体。只需使用一个高质量的翻译引擎并依靠后处理生成替代翻译,就可以避免使用多个引擎的问题。
Semantic Substitution
语义替换是一种非常有效的 post-pass,并且已在以前的方法中用于隐藏信息 [2,5]。与以前工作的一个主要区别是,与原始文本中的语义替换相比,由语义替换引起的错误在翻译中更合理。
传统语义替换的一个典型问题是需要替换列表。替换列表是由语义上足够接近的词组成的元组列表,可以在任意句子中用一个词替换另一个词。对于传统的语义替换,这些列表是手工生成的。语义替换列表中的一对单词的示例将是舒适和方便的。不仅手工构建替换列表很乏味,而且列表中包含的内容也必须是保守的。例如,一般替换列表不能包含诸如明亮和光之类的词对,因为光可以用于不同的意义(意味着轻松、不精确甚至用作名词)。
翻译的语义替换没有这个问题。使用原始句子,可以自动生成语义替换,甚至可以包含上述某些情况(无法添加到一般单语替换列表中)。基本思想是在两种语言之间来回翻译以找到语义相似的单词。假设翻译是准确的,源语言中的单词可以帮助提供必要的上下文信息,以限制对当前上下文中语义接近的单词的替换。
假设源语言是德语(d),翻译的目标语言是英语(e)。原始句子包含一个德语单词 d1 并且翻译包含一个单词 e1,它是 d1的翻译。基本算法如下,如图2所示:
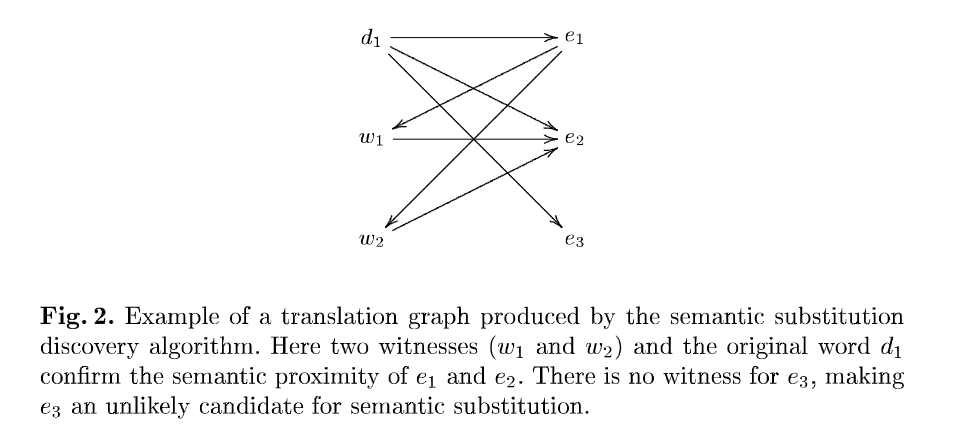
- 找出 d1 的所有其他翻译的集合,并称这个集合为Ed1。 Ed1是语义替换的候选集。e1 ∈ Ed1。
- 找出 e1 的所有翻译;将此集合称为 De1。此集合称为集合witnesses。
- 对于每个单词e ∈ Ed1 − {e1}找到所有的翻译 De1并计算De ∩ De1中元素的数量。如果该数字高于给定的阈值 t,则将 e 添加到 e1 的可能语义替代列表中。
一个witness是源语言中的一个词,它也翻译成目标语言中的两个词,从而确认两个词的语义接近度。witness阈值 t 可用于将更多可能的替换与更高的不适当替换的可能性进行交换。
Adding plausible mistakes
另一种可能的 post-pass 将 MT 系统常见的错误添加到翻译中。我们的实现可以使用的转换基于第 4 节中对 MT 错误的研究。当前系统支持使用手工制作的语言特定替换来更改冠词和介词,这些替换尝试模仿观察到的可能错误。
Results from the Prototype
系统的不同配置产生不同质量的翻译,但即使质量下降也是不可预测的。有时我们的修改实际上(巧合)提高了翻译质量。
应该注意的是,为简单起见,原型当前使用的引擎是公开可用的免费网络引擎,并且这不是自定义生成引擎或付费商业软件的输出的示范。为了更好地说明原型系统,给出了以下稍微更广泛的示例: 24 位字符串“lit”是在来自 Deutsche Welle 网站的电影评论部分的翻译中编码的。使用我们的原型将文本从德语翻译成英语,没有语义替换,启用冠词和介词替换,也没有“不良阈值”。源引擎是 Babelfish、Google 和 LinguaTec。德语文本是一段关于摩洛哥电影《风马》的评论的第一部分,内容如下:
······省略······
Discussion
本节讨论对隐写编码的各种攻击以及针对这些攻击的可能防御。讨论是非正式的,因为该系统基于 MT 的缺陷,这些缺陷很难正式分析(这也是 MT 是一个如此困难的话题的原因之一)。
Future Machine Translation Systems
【所提出的隐写编码在未来可能面临的一个可能问题是机器翻译的重大进展。如果机器翻译变得更加准确,那么可能出现的似是而非的错误可能会变得更小。然而,当前机器翻译错误的一大类是由于机器翻译器没有考虑到上下文。】
为了显着改进现有的机器翻译系统,一个必要的功能是保存从一个句子到下一个句子的上下文信息。只有有了这些信息,才有可能消除某些错误。但是将这种上下文引入机器翻译系统也为在翻译中隐藏信息带来了新的机会。【一旦机器翻译软件开始保留上下文,使用隐写协议的两方就有可能使用这个上下文作为密钥。】通过为各自的翻译引擎植入 k 位上下文,他们可以使翻译中的偏差变得合理,迫使对手可能尝试2k种可能的上下文输入,以便甚至确定使用该机制的可能性。这类似于基于密钥拆分语料库的想法,不同之处在于不会影响每句翻译的整体质量。
Repeated Sentence Problem
在翻译中隐藏消息的任何方法的一个普遍问题是,如果源语言中的文本包含两次相同的句子,它可能会被翻译成两个不同的句子,具体取决于隐藏位的值。由于机器翻译系统(不保留上下文)总是会产生相同的句子,这将允许攻击者怀疑使用了隐写术。解决这个问题的方法是不要在源文本中使用重复的句子来隐藏数据,而始终输出用于该句子第一次出现的翻译。
这种攻击类似于图像隐写术中使用的攻击。如果图像经过数字化修改,图像某些不可信区域的颜色变化可能会揭示隐藏信息的存在。解决这个问题对于文本隐写术来说更容易,因为检测两个句子是否相同比检测图像中的一系列像素属于相同的数字构造形状并因此必须具有相同的颜色更容易。
Statistical Attacks
统计攻击在击败图像、音频和视频的隐写术方面非常成功(参见,例如,[8,14,19])。对手可能有一个统计模型(例如语言模型),所有可用 MT 系统的翻译都遵守该模型。例如,Zipf 定律 [15] 指出,一个单词的频率与其在所有单词的按频率排序的列表中的排名成反比。Zipf 定律适用于英语,事实上,甚至在名词、动词、形容词等个别类别中也适用。
假设所有合理的翻译引擎通常都遵循这样的统计模型,隐写编码器必须小心不要导致与此类分布的明显偏差。一旦知道这样的统计规律,实际上很容易修改隐写编码器以消除明显偏离所需分布的翻译。例如,Golle 和 Farahat [10] 指出(在不同的加密上下文中)可以在不明显偏离 Zipf 定律的情况下广泛修改自然语言文本。换句话说,这是一个非常易于管理的困难,只要隐写系统是“Zipf-aware”的。
我们不能排除尚未发现的翻译语言模型的存在,这些模型可能会被我们现有的实现所违反。然而,我们希望发现和验证这样的模型对于对手来说是一项重要的任务。另一方面,给定这样的模型(正如我们上面指出的)修改隐写系统很容易,通过避免被标记的句子来消除偏差。