那就告一段落吧。
在平衡内心与周遭的过程中,缝缝补补自己眼中千疮百孔的世界……
很多事都不一样了,在表示同意赞赏nb还行的同时,其实内心也在保持着一些最后的倔强甚至不屑的态度。向往诗和远方的同时,也在吐槽当下糟糕的境况。这是暂时的妥协,而不是最后的结果。
可以预见的是,有一天,我也会被一块大饼圈住,为别人给的蛋糕沾沾自喜,因为天上掉的馅饼开始信奉神明,在推杯换盏中周旋,吃饱了面包然后驻足休息,养老等死,我的墓志铭大概就是我的第一个”hello world”代码。这是我最后的倔强,而不是暂时的妥协。
技术无罪,资本作祟的时代,人人都好像鬼怪,争夺面包,吸食人xie,手捧圣经,说着抱歉,最后还不忘总结,口感似乎差了点……
二十一岁我还在对自己说:管他三七二十一,先做自己想做的事,说自己想说的话,走自己想走的路……
时过境迁,我才意识到,这是原来是叫愤青啊。在深感无力的同时,我也只能长叹一口气(很长很长,用英文就是long long long…)。我还以为我在做自己认为对的事情,我在做自己能做到的事情。
每一次成长,都是和自己谈判的过程,而每次妥协都是在塑造新的自己。over!!!
真的不是在吐槽,有认认真真研读!!!
有关:Integrating Linguistic Knowledge to Sentence Paraphrase Generation
论文解读。
模型框架
典型Transformer-based
结构,编码器和解码器都是多个Multi-head Attention
组成。如图:
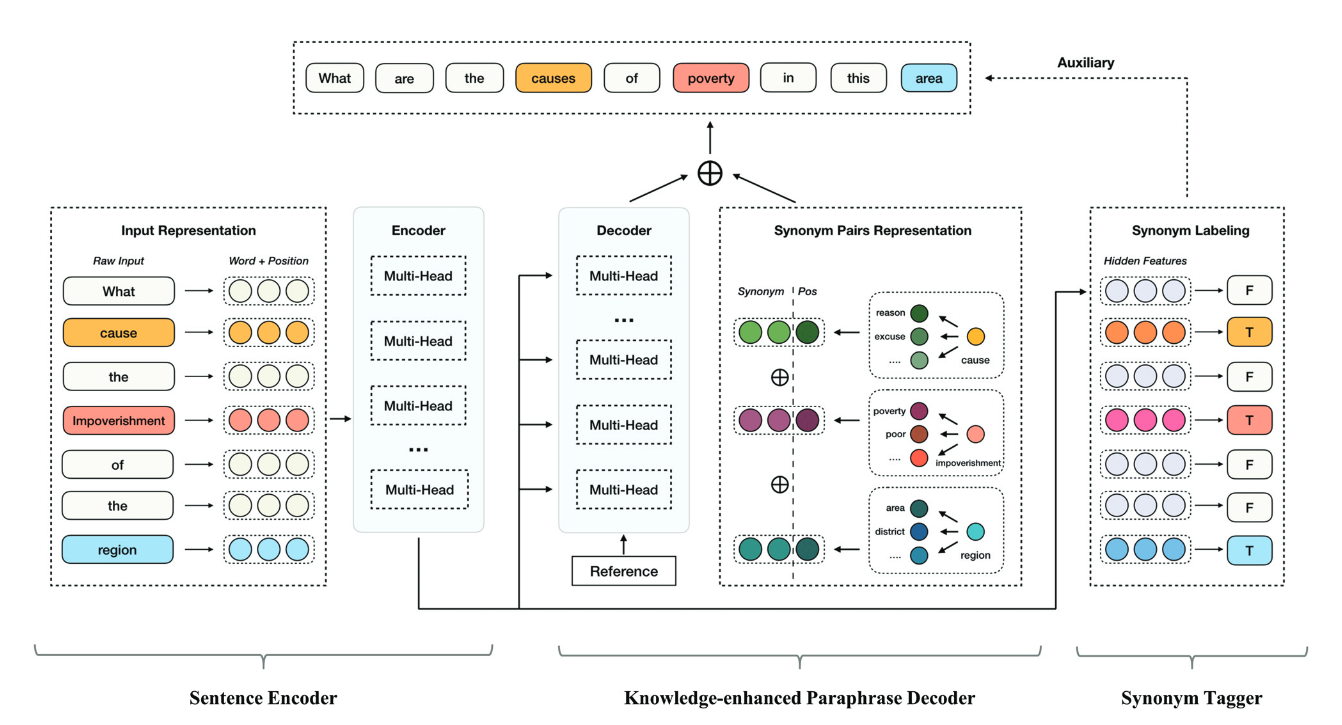
大概分为三个部分:Sentence Encoder、Paraphrase Decoder、Synonym Labeling
按照论文里的思路,模型训练包含了一个辅助任务即:Synonym Labeling
。先用encoder部分做辅助任务训练模型,然后整体训练做生成任务。但其实也是可以一起训练的。
下面结合作者开源的代码进行一些分析。
数据处理
- 第一步
执行 data_processing.py 脚本,生成一个字典文件
vocab 文件。
1 | <pad> |
神奇的是首行的<pad>
并不是脚本添加的,需要自己手动添加,这是运行后面程序发现的。而且多出的<eos>,<sos>
也并没有用到。
- 第二步
执行prepro_dict.py
脚本,生成数据集对应的同义词对文件:train_paraphrased_pair.txt、dev_paraphrased_pair.txt
、test_paraphrased_pair.txt 。
train_paraphrased_pair.txt 为例:
1 | 年景->1 或者->2 年景->4 或->2 抑或->2 要么->2 要->2 抑->2 |
对应train数据集中的第一行是:
1 | 1929 年 还是 1989 年 ? |
具体对应论文中Synonym Pairs Representation
部分:同义词位置对Synonym-position paris 。
词->pos
:其中pos表示sentence
中的位置,词
是指同义词,即句子中pos位置上词对应的同义词。年景->1
中位置1处的词为年 ,年景
即是年的同义词。
- 总结
数据处理这一步两个脚本,生成需要的数据文件有:一个词表文件.vocab
,三个同义词位置对文件_paraphrased_pair.txt 。
整个实验还需要五个数据集文件:train{.src,.tgt},dev{.src,.tgt},test{.src}
最后还想提一下:
tcnp.train.src
第268178行竟然是空行!!!对应同义词对为:<unk>-><unk>
!!! 1
2
3
4
5
6
7
8# tcnp.train.src
268179 阿富汗 肯定 存在 错误 。
268180 在 阿富汗 肯定 有 错误 。
268181 事实上 , 我们 确实 在 阿富汗 犯 了 许多 错误 。
# tcnp.train.tgt
268179 事实上 , 我们 确实 在 阿富汗 犯 了 许多 错误 。
268180 阿富汗 肯定 存在 错误 。
268181 在 阿富汗 肯定 有 错误 。
train 训练
训练部分代码:
1 | def train(self, xs, ys, x_paraphrased_dict, synonym_label=None): |
大概流程就是: encoder -> labeing and decoder 。
Sentence Encoder
输入:
- sentence x token [x1,x2,x3,…,xn]
输出:
- memory: 经过多个Multi-head Attention后的输出
和常规的transformer encoder一样。先是对句子token向量进行embedding,然后添加位置编码positional_encoding。
对应代码在:model.py :
1 | def encode(self, xs, training=True): |
不过有趣的是论文中关于Encoder的部分貌似有些问题:
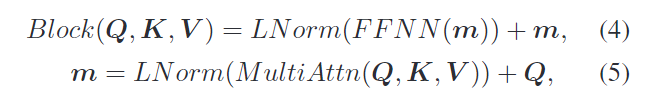
这是论文中的式子。在transformer中是这样的:Block(Q,K,V) = LNorm(FFN(m)+m)、m=LNorm(MultiAttn(Q,K,V)+Q)
。先add再norm啊!!!
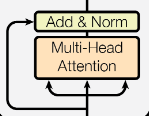
不知道是不是排版错误的原因。主要作者开源的代码里multihead_attention部分还有ffn
部分是先add再norm的。
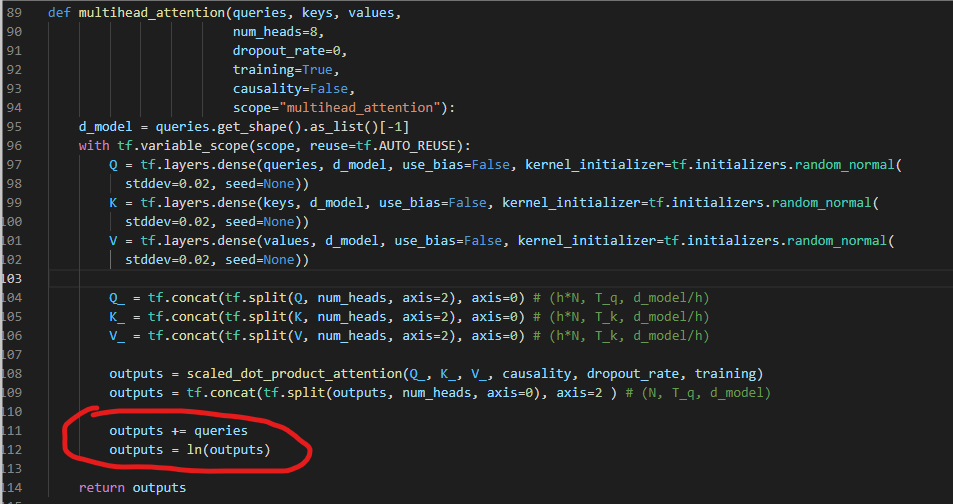
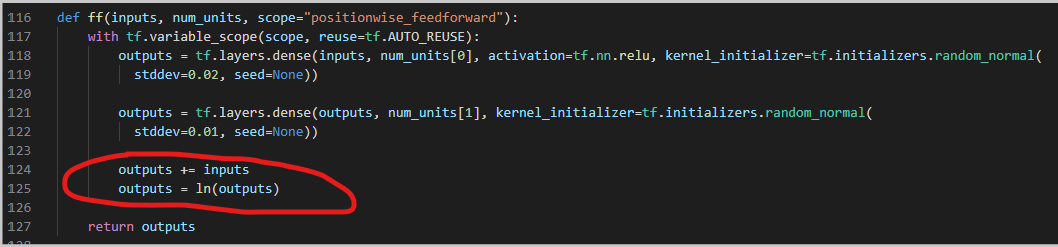
属实给整蒙了。
Paraphrase Decoder
输入:
- sentence y token [y1,y2,y3,…,ym] 对应tgt中的句子的token
- x_paraphrased_dict
引入的外部知识,也就是同义词位置对:
synonyms- position pairs - memory: 编码器的输出
输出:
- logits, y_hat:
logits是最后一层的输出,y_hat是预测值
这部分有self-attention 、vanilla attention、paraphrased dictionary attention。
self-attention部分和原本的transformer中一样,key=value=query。vanilla
attention其实就是key与value相同,query不一样。paraphrased dictionary
attention就是引入外部同义词字典知识的部分。这部分主要是计算论文中ct
,按论文中公式来即可。
对应代码在:model.py :
1 | def decode(self, ys, x_paraphrased_dict, memory, training=True): |
在最后的输出层部分:论文中的 softmax layer:
yt = softmax(WyConcat[yt*, ct]))
代码中很巧妙的使用 tf.transpose(self.embeddings)
来表示Wy 从而将输出映射到vocab输出。
这里需要注意的是x_paraphrased_dict的表示。论文中叫做synonyms- position pairs,使用P
表示。 P = (si, pi)i = 1M
si 表示同义词,pi
表示同义词对应sentence中的位置。训练时,会将si
进行embedding ,pi
进行位置编码positional_encoding
。这里的embedding 与positional_encoding
和encoder部分共享。
Synonym Labeling
输入:
- synonym_label:同义词标签
- memory: encoder的输出
输出:
- logits, y_hat, loss: 一个全连接层的输出、一个预测值、一个损失
synonym_label:[True,False,…],对于给定的一个句子,如果句中词对应位置有同义词这对应label为True,否者为False。这一部分的loss对应论文中的loss2。
这是一个辅助任务,目的是确定给定句子中每个词是否有对应的同义词。有助于更好地定位同义词的位置,结合短语和同义词在原句中的语言关系。可以肯定的是,这是一个二分类任务,并且两个任务共用一个encoder。描述如下:

对应代码:
1 | def labeling(self, x, menmory): |
需要注意的是代码中还有def train_labeling(self, xs, synonym_label=None):
的地方。按照论文中的描述:

这个函数是用来单独做Synonym Labeling
任务的。按论文中的原意,应该是先model.train_labeling(xs, synonym_label)
然后
在进行model.train(xs, ys, x_paraphrased_dict, synonym_label)。
但是train.py
代码中并没有这样做。而是直接进行train 。
有关细节问题
- vocab
前面提到过,生成的词表中多出<sos>,<eos>
两个没有用到的词,少了用于填充的<pad>,并且需要自己在首行手动插入<pad>
。猜测可能是课题组的祖传代码。
而且在生成同义词位置对的文件的代码那里,将不在vocab中的同义词统统过滤掉了。
- Synonym Pairs Representation

论文里提到如果对应同义词是一个短语,那么就将短语中词嵌入向量求和来表示该短语的向量表示。但是!!!有意思的是,代码中并未体现。而细挖他的数据会发现,给定的数据已是分好词的按空格分隔的。而且是中文数据。中文分好的词,如果是短语,分词后,还是表示一个词。而英文如:abandon同义词give up。give up分词后就是两个单词。也就出现上述情况。
因此,得出结论,作者开源的代码是不完整的。如果换成英文的数据,那么需要考虑的复杂一些了。当然也可以选择把短语同义词过滤掉,那么和中文上处理就是一样的了。
- paraphrase_type
paraphrase_type这个是代码中的一个配置参数,默认为1。
parser.add_argument('--paraphrase_type', default=1, type=int)
这是所有参数中为数不多没有help提示信息的参数。并且我相信这也是唯一一个没有help整不明白的参数。释义类型?
在data_load.py 中找到了蛛丝马迹:
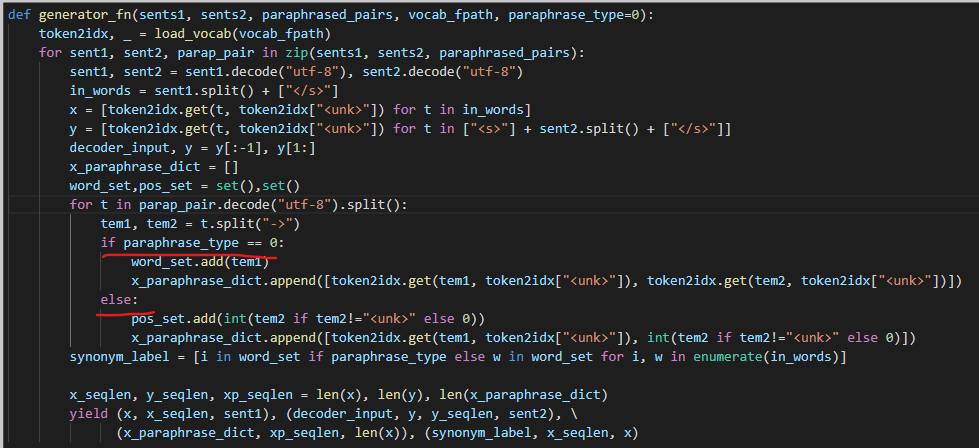
而这一段代码,也属实有些魔幻。
首先parser.add_argument('--paraphrase_type', default=1, type=int)
这里使用的是1。而取值为1时,对应代码中esle:部分。不用很仔细就可以看出:0时,使用word_set,1时,使用pos_set。我们在观察后面的synonym_label
那一句:
synonym_label = [i in word_set if paraphrase_type else w in word_set for i, w in enumerate(in_words)]
码字到这里,我掐了以下人中,方才缓过神来。接着分析,为0的情况下,那么考虑w in word_set
的真值情况。而for i, w in enumerate(in_words)
,w属于in_words。word_set是什么呢?word_set.add(tem1)
哇哦,是同义词集合诶,in_words是什么?in_words=sent1.split()+['</s>']
欸,那w难道不是don’t exit in word_set forever?
离谱的是,这里讨论的是paraphrase_type = 1的情况,也就是关word_set屁事的情况。word_set这时都是空的。所以synonym_label 难道不是always be False 。
Are you kidding me? %$*#@>?*&。。。。
而且x_paraphrase_dic 那里也是有问题的。
x_paraphrase_dict.append([token2idx.get(tem1, token2idx["<unk>"]), token2idx.get(tem2, token2idx["<unk>"])])
这个token2idx.get(tem2, token2idx["<unk>"])
就很有问题,tem2表示的是pos啊,句子中词的位置,直接给我token2idx
我是无法理解的。
x_paraphrase_dict.append([token2idx.get(tem1, token2idx["<unk>"]), int(tem2 if tem2!="<unk>" else 0)])
int(tem2 if tem2!="<unk>" else 0)
也就是说tem2为<unk>
时,大概就是tem2取0的意思。而tem2出现<unk>
的情况时,tem1也是<unk>
。此时x_paraphrase_dict添加的就是[1, 0]
(token2idx[“
1 | 句子x: x1 x2 x3 x4 。 |
这表示这个句子中没有词含有同义词。这个时候x_paraphrase_dict添加[1, 0],就相当于<unk>
为 x1的同义词。这怎么可能?It’s impossible!!!
而且就很不reasonable 。简直离谱!!!离了个大谱。
甚至这段代码的第二个for循环后面的那部分代码逻辑都是有问题的。synonym
labeling 任务我认为是有问题的。而将<unk>
与位置0处单词绑定,本身就引入了一些噪声,甚至可能增加<unk>
释义的潜在可能性。至于模型能work,我想,synonym
labeling本身作为辅助任务,其loss权值占比为0.1,影响应该是很小的。
这里大胆揣测以下paraphrase_type 意图:
- paraphrase_type = 0时:x_paraphrase_dict包含句子中的词以及对应同义词,不含位置信息。
- paraphrase_type = 1 时: x_paraphrase_dict其实包含同义词以及对应位置pos。
无论哪一种情况,其实都是在做一件事:就是将词与其对应的同义词之间进行绑定。第一种更像是比较直接的方式,第二种则略显委婉点。殊途同归!!!
不管是不是这两种情况,其实那块代码都是有问题的。
- 有关 paddings
data_load.py 中有段这样的代码,用来获取一个batch size
数据的dataset函数:
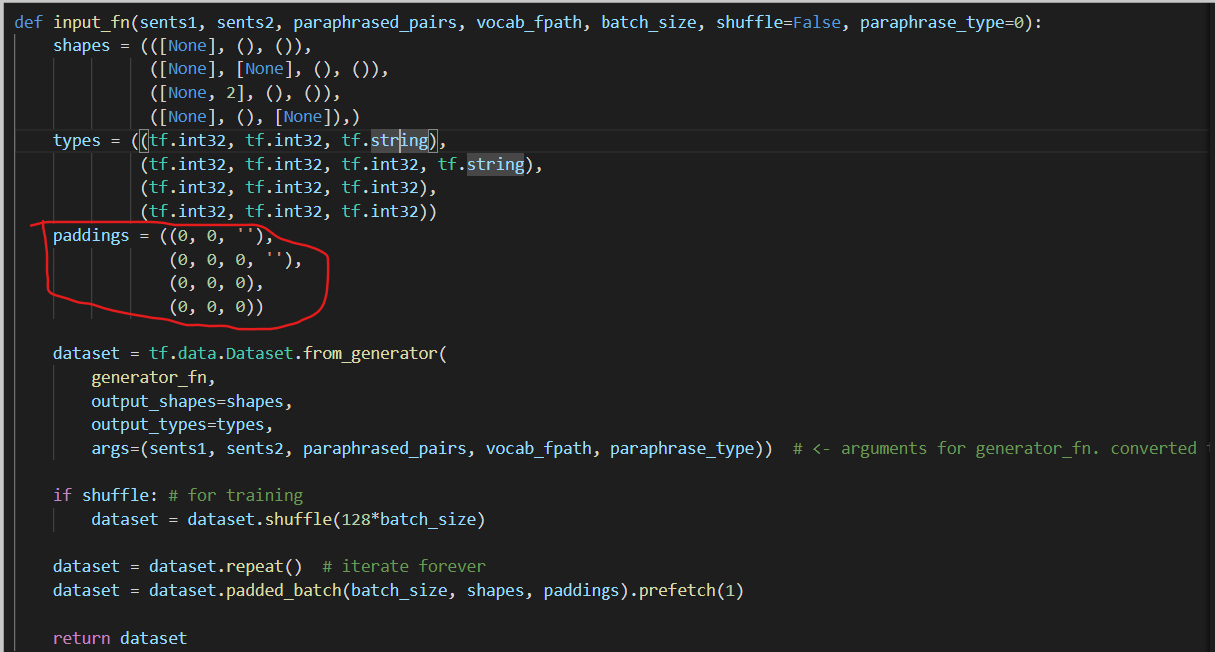
其中关于paddings
处的地方自认为还是有些不妥的,对于src、tgt句子进行0填充是正常操作,但是对于x_paraphrased_dict也进行0填充是欠考虑的。
对于x_paraphrased_dict
,0填充,就会出现一部分[[0,0],[0,0],…]的情况
默认将[pad]字符与位置0的词对应了。
总结
这篇论文做的是: Sentence Paraphrase Generation 。
其中真正核心地方在于 Knowledge-Enhanced ,知识增强。主要就是通过引入外部信息(这里是同义词字典信息)来指导模型生成更加多样性的句子。关于知识增强的方式还是有很多的,这篇论文采用的应该是词表注意力机制,得到外部信息特征表示ct 。
代码开源了,貌似有没有完全开源!!!
开源的代码基于python3.6 + tensorflow-gpu==1.12。调试起来真的好麻烦。看不惯tf1.x的代码风格,然后用tf2.x复现了下。
- 对于 paraphrase_type 的两种情况按上述理解做了调整。
- 对
<unk>匹配第一个单词的情况进行纠正,将tme2 = <unk>时(句子中没有词存在同义词的情况),用第一个词与第一个词匹配。即将x1的同义词匹配为x1,这样还是比较妥当的。 - 过滤了空行,减少不必要的噪声。(空行对应的同义词对为 <unk>-><unk>)
- synonym_label中使用2进行padding。训练时,是需要对其进行padding的保证输入的数据工整的。比如句子idx会使用0进行填充直到maxlen,而idx=0对应词为
<pad>。显然,<pad>和其他词一样,是一个单独的类别了。所以,为了区分,synonym_label的padding_value设置为2。最后做成一个三分类任务。无伤大雅,主要是为了适配句子的填充。 - 为了适应
x_paraphrased_dict的0填充,对输入句子src的首位置引入一个填充符<pad>。这一点与第二点先呼应。
不知道效果如何,小作坊,资源有限,训练完要很久很久。敬佩所有敢于开源代码的科研人员,也希望所有开源代码可读性越来越好吧。也希望所有开源代码都能复现结果。至少把种子固定了吧!!!
————————————–——–———-———10月16日更——————-–—-———————————————
一点思考
兜兜转转,模型训练了好几遍,从训练指标来看,loss有下降,acc有升高,但是推理的时候,预测的起始符号<s>后一个词总是结束符</s>
。debug无数遍,优化了一些细节上的小问题,还是出现那样的情况。最后将问题锁定在了padding_mask
和look_ahead_mask
上,其实最可能猜到就是look_ahead_mask
有问题。此处的mask都是0和1填充的,代码中使用了tf.keras.layers.MultiHeadAttention
接口,对于0、1矩阵的mask,在里面并没有进行mask*-1e9
的掩码操作,这也导致了训练时出现了数据穿越/泄露问题。所以在推理时,输入的起始字符进行预测时不能得到正确结果,至于为什么是结束符,可能是起止符在词表中相邻的缘故。
今天改好后,重新训练,十多个小时过去了,还没训练完(3090,24G显存)。
如今的顶会基本被财大气粗的大公司大实验室的团队承包,小作坊式实验室夹缝求生。顶会期刊也不乏滥竽充数者,实验结果复现难,开源名存实亡……等等一系列骚操作。现有大环境下,一言难尽。
————————————–——–———-———10月17日更——————-–—-———————————————
开完组会,被老师叫停,没有硬件资源,也只好先放弃,把其他事情提上日程。
