Lost in just the translation
摘要
本文介绍了自然语言翻译文本信息隐藏系统的设计与实现,并给出了实验结果。与前人的工作不同,本文提出的协议只需要翻译文本就可以恢复隐藏信息。这是一个重大的改进,因为传输源文本既浪费资源又不安全。现在,系统的安全性得到了改善,这不仅是因为源文本不再对敌方有用,还因为现在可以使用更广泛的防御系统(如混合人机翻译)。
协议
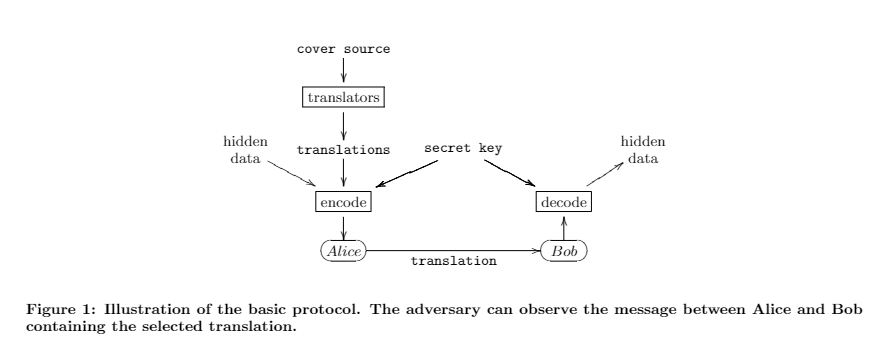
Producing translations
方法大致与论文【Translation-Based Steganography】中提到的一样
Tokenization
双方使用相同的 Tokenization 算法,以获得相同的句子序列
Choosing h
选择合适的 h (h ≥ 0),h表示将信息隐藏在每个句子中的长度的位数。
Selecting translations
对于所有翻译,编码器首先使用与接收方共享的密钥计算每个翻译的加密键值散列。其基本思想是在给定句子的所有译文中选择一个句子,然后对其进行适当的长度编码,并在隐藏的信息中选择合适的位置。然而,由于给定句子中的位编码数量是可变的,因此该算法在这方面有很大的自由度。
Optimized Handling of Hash Collisions
哈希冲突的处理优化
总结
为了不传输源文本,从而,引入了哈希映射和 Tokenization以及参数 h。产生翻译文本过程中混合人机翻译结果,使得隐藏的信息更加难以检测。