论文:GENERALIZATION THROUGH MEMORIZATION: NEAREST NEIGHBOR LANGUAGE MODELS
code:knn-lm
论文的主要思想是使用传统 knn 算法对预训练神经语言模型进行线性插值扩展。
ps:传统算法在这个深度学习领域的一次融合……印象中,都是使用预训练模型在小数据集上进行微调,这篇论文似乎有点东西。
对于语言模型LM,给定一个上下文序列tokens: ct = (w1, ..., wt − 1) 自回归语言模型通过建模p(wt|ct) 来预测目标词 wt 的概率分布。
kNN-LM可以在没有任何额外的训练情况下,用最邻近检索机制增强预训练语言模型。在模型预训练后,会对训练集的文本集合进行一次前向传播,任何得到 context-target pairs,并将其以键值对形式存储起来(a key-value datastore),以便在推理过程中查找。
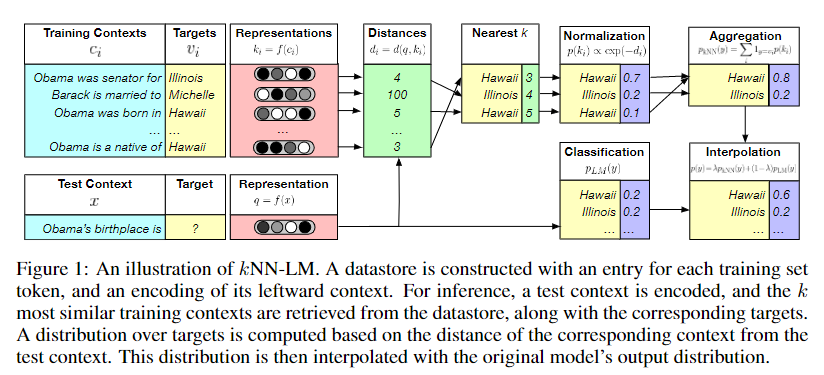
具体的:设语言模型为 f(·),可以将一个上文 c 映射为固定长度的向量表示。对于给定的第 i 个训练样本(ci, wi) ∈ D ,定义一个键值对(ki, vi) ,ki 表示上文ci 的向量表示,vi 表示目标词wi ,datastore (K, V)表示这样一个集合: (K, V) = {(f(ci), wi)|(ci, wi) ∈ D} 在推理阶段,对于给定上文信息 x ,预测 y 概率分布。使用knn算法进行插值,有: $$ p(y|x) = \lambda p_{knn}(y|x) + (1-\lambda)p_{LM}(y|x)\\ p_{knn}(y|x) \propto \sum_{(k_i,v_i)\in N} 1_{y=v_i}exp(-d(k_i,f(x)))\\ $$ λ 表示调谐参数,N表示更具距离得到的k邻近集合。距离计算公式采用欧氏距离(L2范数)。在这里knn只是为了得到集合N。
当然这种使用knn算法的方法不免存在一些算法本身的缺点。一是距离计算公式的选择,二是查询速度,三是k的选择。对于一个预训练语言模型,需要的语料是巨大的,该方法需要将训练集语料的所有键值对保存下来,便于查询。可想而知,从如此巨大的键值对中获取 k 近邻集合N,其查询代价是相当巨大的!!!
正因如此,为了knn-lm更好的work,在实现时,使用了FAISS库来加速查询过程。
一点补充
原本看完论文后,我就知道这个保存的datastore是很大的,但是我没想到这大的如此离谱!!!
readme中提到模型训练使用了8块GPU,而且基于是Fairseq的。脑阔疼,对Fairseq本来就没什么好印象。索性他提供了一个checkpoint,可以跳过模型训练部分了。但看到后面生成datastore时,我。。。
Caution: Running this step requires a large amount of disk space (400GB!). Please read the note about hardware above, before running this!
400GB的磁盘大小!!!!!真的是离了一个大谱!!!!!!
现在想想论文摘要里的那句:
our kNN-LM achieves a new state-of-the-art perplexity of 15.79 – a 2.9 point improvement with no additional training.
这让我不得不怀疑,这sota拼的是磁盘大小啊。真的是有点东西,我一个小作坊,GPU都就是白嫖的,现在整个400G磁盘,我也是活久见。
一个小故事
我本一介凡人,但是一心向往修仙炼丹之术。早闻各路大神每年都会在修仙圣地 ICLR 交流切磋修仙炼丹心得。 一次偶然机会,受高人指点,得到一本秘籍。看完秘籍,豁然开朗,炼丹之路,似乎有了些盼头。
欣喜之余,我也丝毫不敢懈怠。靠着几年的游历经验,白嫖到了一些炼丹器具,也习得一门奇门遁术python,更是窥得仙术tensorflow和pytorch几分奥秘,python大法从入门到入坑,深度学习从入门到放弃,从删库到跑路,我虽自认为资质平庸,在江湖掀不起大风大浪,却也勤勤恳恳苦心修炼,也是到了初识境界。
Github,无数修仙能人术士炫技圣地,在这里果然找到了秘籍之中提到的各种原料以及使用说明书(大神们愿称之为 ‘瑞德密’)。
于是开始每天起早贪黑,备药材,烧丹炉,研究秘籍。按照瑞德密一步一步修炼,但是依旧失败了一次又一次。深感才疏学浅带来的无力,莫不是修为尚浅,无法领略其中奥义。夜不能寐,辗转反侧,我仍百思不得其解。
偶然间,看到到瑞德密后面部分,再次豁然开朗:
欲修此术修此丹药,需备八个丹炉,外部容器非四百G不可。
感觉像是吃了闭门羹,无数人对修仙炼丹之术趋之若鹜,但真正修得正果的,基本是各大财大气粗的门派的人。而对于资质平凡,财力有限的小作坊而言,这条路似乎走的异常艰辛。曾无数次阅读各路大神秘籍,但因为各种苛刻的修炼条件望而却步。