Sequence to Sequence Learning with Neural Networks
基于神经网络的seq2seq
很好的解决了序列到序列之间的映射问题,在语音识别和机器翻译这种长度未知且具有顺序的问题能够得到很好的解决。该模型应用到英语到法语的翻译任务,数据集来自WMT’14,在整个测试集上的BLEU得到达到34.8。
模型结构:
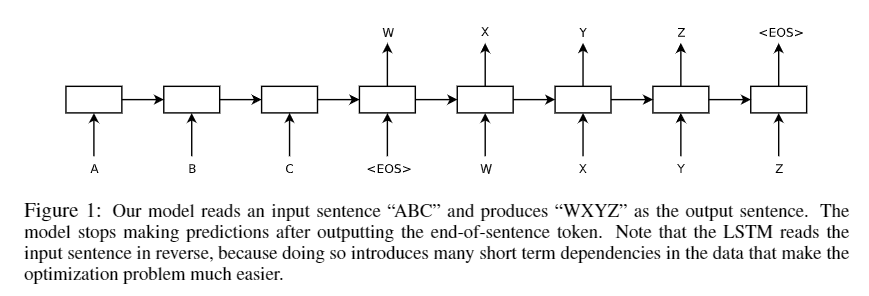
这里使用了两个串联的 lstm 网络,前一个用于读取输入序列,产生一个大的固定维度的向量表示,然后再用一个lstm 网络从向量表示中提取输出序列。一个编码器(Encoder),一个解码器(Decoder)。
值得注意的是,论文提到在实现时,有三点与 lstm 不一样。【Our actual models differ from the above description in three important ways.】
- 使用两个不同的lstm
- 4层 lstm
- 将输入序列进行反转【a,b,c —> c,b,a】【PS: 这就是传说中的反向操作吗?!莫名其妙的trick,滑稽.jpg】
目标函数: $$ \frac{1}{|S|}\sum_{(T,S)\in S}logP(T|S) $$ S为训练集,T表示正确的翻译。训练结束后,进行翻译时,在模型产生的多个翻译结果中找到最可能正确的翻译: T̂ = argmaxTP(T|S) 通过一个简单的 left-to-right beam search 解码器(decoder)搜索最可能的翻译。
We search for the most likely translation using a simple left-to-right beam search decoder which maintains a small number B of partial hypotheses, where a partial hypothesis is a prefix of some translation. At each timestep we extend each partial hypothesis in the beam with every possible word in the vocabulary. This greatly increases the number of the hypotheses so we discard all but the B most likely hypotheses according to the model’s log probability. As soon as the “
” symbol is appended to a hypothesis, it is removed from the beam and is added to the set of complete hypotheses. While this decoder is approximate, it is simple to implement. Interestingly, our system performs well even with a beam size of 1, and a beam of size 2 provides most of the benefits of beam search(Table 1).
一个小的总结
总的来说, Reversing the Source Sentences 这个操作给模型带来了很大的提升。
the LSTM’s test perplexity dropped from 5.8 to 4.7, and the test BLEU scores of its decoded translations increased from 25.9 to 30.6.
至于为什么,论文中也没有给出很好的解释(大概是说,反转后,前面源句子的前几个词与目标句子的前几个词距离更近,模型能更好收敛。【a,b,c |w,x,y—> c,b,a|w,x,y】w,x,y为a,b,c对应的翻译,反转后,a,b,c与w,x,y的平均距离不变,a离w更近了。但是c离y更远却没有影响模型精度。可能这就是玄学吧?!)。【PS:难道是因为误打误撞的尝试然后发现效果惊人,然后就发论文了?不过这篇论文确实奠定了之后的seq2seq模型的基础。】