赛题:蛋白质结构预测挑战赛
数据集一共包含245种折叠类型,11843条蛋白质序列样本,其中训练集中有9472个样本,测试集中有2371个样本。
继上次lgb的base模型 后,尝试过word2vec + 神经网络的方法,最后效果甚微。今天尝试了一下双向GRU模型,相比之前,有几个百分点的提高。
代码:
1 | import numpy as np |
提交结果:目前【39/130(提交团队数)】

赛题:蛋白质结构预测挑战赛
数据集一共包含245种折叠类型,11843条蛋白质序列样本,其中训练集中有9472个样本,测试集中有2371个样本。
继上次lgb的base模型 后,尝试过word2vec + 神经网络的方法,最后效果甚微。今天尝试了一下双向GRU模型,相比之前,有几个百分点的提高。
代码:
1 | import numpy as np |
提交结果:目前【39/130(提交团队数)】
Effective Approaches to Attention-based Neural Machine Translation
基于注意力机制的神经机器翻译的有效方法
Bib TeX
@inproceedings{luong-etal-2015-effective, title = “Effective Approaches to Attention-based Neural Machine Translation”, author = “Luong, Thang and Pham, Hieu and Manning, Christopher D.”, booktitle = “Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing”, month = sep, year = “2015”, address = “Lisbon, Portugal”, publisher = “Association for Computational Linguistics”, url = “https://aclanthology.org/D15-1166”, doi = “10.18653/v1/D15-1166”, pages = “1412–1421”, }
在神经机器翻译中引入注意力机制(Attention),使模型在翻译过程中选择性的关注句子中的某一部分。本文研究了两种简单有效的注意力机制。
global attention 类似方法[1],但架构上更加简单。local attention 更像是 hard and soft attention [2]的结合。两种方法在英德语双向翻译任务中取得了不错的成绩。与已经结合了已知技术(例如 dropout)的非注意力系统相比,高了5.0个BLEU点。在WMT’15英语到德语的翻译任务中表现 SOTA(state-of-the-art)。
With local attention, we achieve a significant gain of 5.0 BLEU points over non-attentional systems that already incorporate known techniques such as dropout. Our ensemble model using different attention architectures yields a new state-of-the-art result in the WMT’15 English to German translation task with 25.9 BLEU points, an improvement of 1.0 BLEU points over the existing best system backed by NMT and an n-gram reranker.
模型结构:
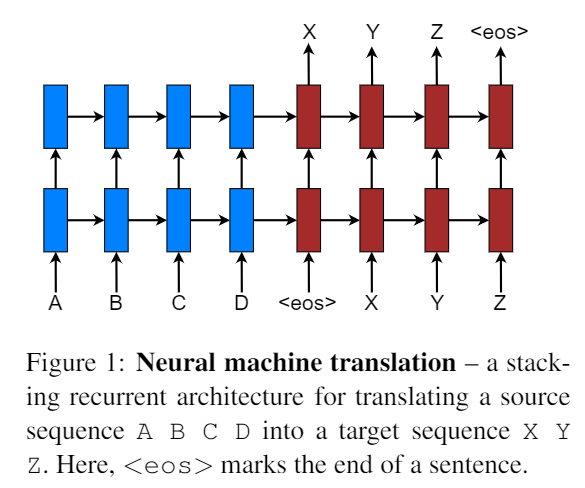
采用堆叠的 LSTM结构[3]。其目标函数为: Jt = ∑(x, y) ∈ D − logP(y|x) D为训练的语料。x 表示源句子,y表示翻译后的目标句子。
这部分包括两种注意力机制:global 和 local。两种方式在解码阶段,将使用堆叠LSTM顶层的隐藏状态 ht 作为输入。区别在于获取上下文向量表示ct方法不同。然后通过一个 简单的 concatenate layer 获得一个注意力隐藏状态ĥt: ĥt = tanh(Wc[ct; ht]) 最后通过 softmax layer 得出预测概率分布: p(yt|y < t, x) = softmax(Wsĥt) Global Attention
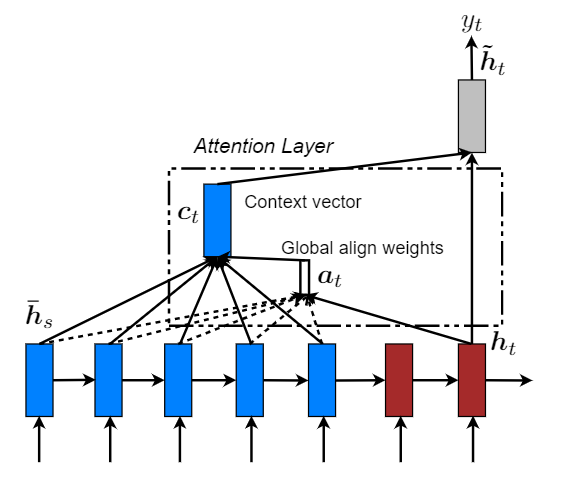
主要思想是通过编码器的所有隐藏状态(hidden state)来获取上下文向量(context vector)表示 ct。可变长度对齐向量at通过比较当前目标隐藏状态ht和每个源隐藏状态$\overline h_s$得到: $$ a_t(s) = align(h_t,\overline h_s)=\frac{exp(score(h_t,\overline h_s))}{\sum_{s'}exp(h_t,\overline h_{s^{'}})} $$ score被称为 content-based 函数: $$ score(h_t,\overline h_s)=\begin{cases} h_t^{T}\overline h_s, dot\\ h_t^{T}W_a\overline h_s, general\\ W_a[h_t;\overline h_s], concat \end{cases} $$ 与[1]的区别在于:
Local Attention
global 模式下,模型需要关注全局信息,其代价是非常大的。因此也就出现了 local attention。让注意力机制只去关注其中的一个子集部分。其灵感来自于 [2]。
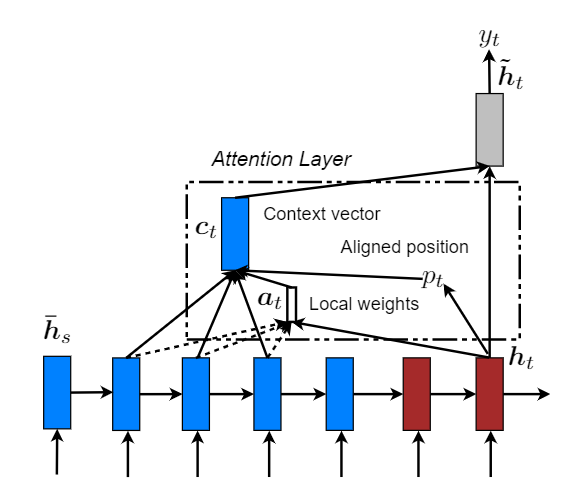
对比两张模型图来看,其中的局部对齐权重at由一部分局部隐藏状态计算得到,其长度变成了固定的,并且还多了一个Aligned position pt ,然后上下文向量(context vector) ct 由窗口[pt − D, pt + D]内的隐藏状态集合的加权平均得到。其中D根据经验所得。
考虑两种变体:
Monotonic alignment (local-m)
即简单设置 pt = t ,认为源序列于目标序列是单调对齐的,那么at 其实就和公式(4)计算方法一样了。
Predictive alignment (local-p)
pt = S · sigmoid(vpTtanh(Wpht)) ,vp和Wp是预测pt 的模型参数。S为源句子长度。最后pt ∈ [0, S] 。同时为了使对齐点更靠近pt,设置一个以pt为中心 的高斯分布,即at 为:$a_t(s)=align(h_t,\overline h_s)exp(-\frac{(s-p_t)^2}{2\sigma^2}),\sigma=\frac{D}{2}$,s为高斯分布区间内的一个整数。
这一部分,主要是为了捕获在翻译过程中哪些源单词已经被翻译过了。对齐决策应当综合考虑过去对齐的信息。该方法将注意力向量ĥt 作为下一个时间步的输入。主要有两个作用:
整篇论文看下来,大概就是在别人的baseline中引入注意力机制(global and local),然后使用Input-feeding 方法将过去的对齐信息考虑进来(大概就是加入了一个先验知识吧)。【PS:震惊!这些创新的点的灵感都来自其让人的论文中的方法。】
最后手动滑稽:
Attention is all you need!
[1] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. InICLR.
[2] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron C. Courville, Ruslan Salakhutdinov, Richard S. Zemel, and Yoshua Bengio. 2015. Show,attend and tell: Neural image caption generation with visual attention. InICML.
[3] Wojciech Zaremba, Ilya Sutskever, and Oriol Vinyals. 2015. Recurrent neural network regularization. InICLR.
Sequence to Sequence Learning with Neural Networks
基于神经网络的seq2seq
很好的解决了序列到序列之间的映射问题,在语音识别和机器翻译这种长度未知且具有顺序的问题能够得到很好的解决。该模型应用到英语到法语的翻译任务,数据集来自WMT’14,在整个测试集上的BLEU得到达到34.8。
模型结构:
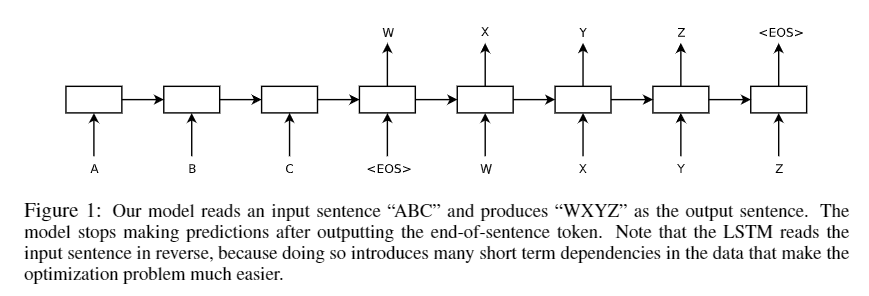
这里使用了两个串联的 lstm 网络,前一个用于读取输入序列,产生一个大的固定维度的向量表示,然后再用一个lstm 网络从向量表示中提取输出序列。一个编码器(Encoder),一个解码器(Decoder)。
值得注意的是,论文提到在实现时,有三点与 lstm 不一样。【Our actual models differ from the above description in three important ways.】
目标函数: $$ \frac{1}{|S|}\sum_{(T,S)\in S}logP(T|S) $$ S为训练集,T表示正确的翻译。训练结束后,进行翻译时,在模型产生的多个翻译结果中找到最可能正确的翻译: T̂ = argmaxTP(T|S) 通过一个简单的 left-to-right beam search 解码器(decoder)搜索最可能的翻译。
We search for the most likely translation using a simple left-to-right beam search decoder which maintains a small number B of partial hypotheses, where a partial hypothesis is a prefix of some translation. At each timestep we extend each partial hypothesis in the beam with every possible word in the vocabulary. This greatly increases the number of the hypotheses so we discard all but the B most likely hypotheses according to the model’s log probability. As soon as the “
” symbol is appended to a hypothesis, it is removed from the beam and is added to the set of complete hypotheses. While this decoder is approximate, it is simple to implement. Interestingly, our system performs well even with a beam size of 1, and a beam of size 2 provides most of the benefits of beam search(Table 1).
一个小的总结
总的来说, Reversing the Source Sentences 这个操作给模型带来了很大的提升。
the LSTM’s test perplexity dropped from 5.8 to 4.7, and the test BLEU scores of its decoded translations increased from 25.9 to 30.6.
至于为什么,论文中也没有给出很好的解释(大概是说,反转后,前面源句子的前几个词与目标句子的前几个词距离更近,模型能更好收敛。【a,b,c |w,x,y—> c,b,a|w,x,y】w,x,y为a,b,c对应的翻译,反转后,a,b,c与w,x,y的平均距离不变,a离w更近了。但是c离y更远却没有影响模型精度。可能这就是玄学吧?!)。【PS:难道是因为误打误撞的尝试然后发现效果惊人,然后就发论文了?不过这篇论文确实奠定了之后的seq2seq模型的基础。】
Lost in just the translation
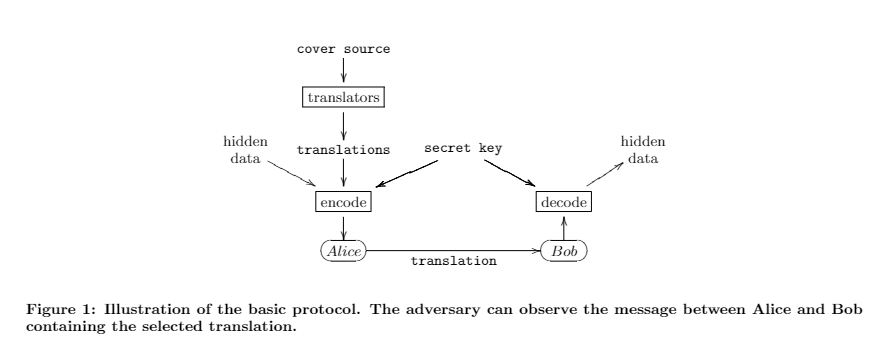
本文介绍了自然语言翻译文本信息隐藏系统的设计与实现,并给出了实验结果。与前人的工作不同,本文提出的协议只需要翻译文本就可以恢复隐藏信息。这是一个重大的改进,因为传输源文本既浪费资源又不安全。现在,系统的安全性得到了改善,这不仅是因为源文本不再对敌方有用,还因为现在可以使用更广泛的防御系统(如混合人机翻译)。
Producing translations
方法大致与论文【Translation-Based Steganography】中提到的一样
Tokenization
双方使用相同的 Tokenization 算法,以获得相同的句子序列
Choosing h
选择合适的 h (h ≥ 0),h表示将信息隐藏在每个句子中的长度的位数。
Selecting translations
对于所有翻译,编码器首先使用与接收方共享的密钥计算每个翻译的加密键值散列。其基本思想是在给定句子的所有译文中选择一个句子,然后对其进行适当的长度编码,并在隐藏的信息中选择合适的位置。然而,由于给定句子中的位编码数量是可变的,因此该算法在这方面有很大的自由度。
Optimized Handling of Hash Collisions
哈希冲突的处理优化
为了不传输源文本,从而,引入了哈希映射和 Tokenization以及参数 h。产生翻译文本过程中混合人机翻译结果,使得隐藏的信息更加难以检测。
Translation-Based Steganography
基于翻译的隐写术
这篇论文研究了用隐写术在自然语言文档自动翻译产生的噪音(“noise”)中隐藏信息的可能性。由于自然语言固有的冗余性为翻译的变化创造了足够的空间,因此机器翻译非常适合隐写。此外,因为在自动文本翻译中经常出现错误,信息隐藏机制插入的额外错误就很难检测出来,看起来就像是翻译过程中产生的正常噪音的一部分。正因如此,我们是很难确定翻译中的不准确是由隐写术的使用还是由翻译软件的缺陷造成的。
本文提出了一种用于自然语言文本中的隐蔽消息传输的新协议,为此我们有一个概念验证(proof-of-concept )实现。关键点就是将信息隐藏在自然语言翻译中经常出现的噪音中。在一对自然语言之间翻译[non-trivial]文本时,通常有许多可能的翻译结果。【大概意思应该是在不改变原文意思的情况下,翻译的结果是多种多样的】。选择这些翻译结果之一就可用于对信息进行编码。一个 adversary 要想检测出其中隐藏的信息,就必须明白包含隐藏信息的翻译是不可能由普通翻译生成的。由于翻译过程中本就夹杂一些噪声,这使得检测隐藏信息是十分困难的。例如,由于同义词的存在,在对原文进行翻译的过程中,使用同义词进行替换。随着翻译结果的增加,也增加了信息隐藏的可能性。
本文评估了使用自动机器翻译 (MT) 的自然语言翻译中隐蔽消息传输的潜在性。为了描述在机器翻译中的哪种变化是合理的,我们研究了各种 MT 系统产生的不同类型的错误。在机器翻译中观察到的一些变化对于人工翻译也显然是合理的。除了让 adversary 难以检测到隐藏信息的存在之外,基于翻译的隐写术也更容易使用。与之前的基于文本、图像和声音的隐写系统不一样,基于翻译的隐写,其 cover 是不需要保密的【the cover does not have to be secret.】。在基于翻译的隐写术中,源语言的原始文本可以是公开的,可以从公共资源中获取,并与译文一起,在adversary的视线范围内,在两方之间进行交换。在传统的图像隐写术中,经常出现的问题是,随后隐藏消息的源图像必须由发送者保密并且只使用一次(否则“diff”攻击将揭示隐藏消息的存在)。这增加了用户为每条消息创建新的秘密封面(secret cover)【周杰伦的专辑《不能说的秘密》?!滑稽脸.jpg】的负担。
In translation-based steganography, the original text in the source language can be publically known, obtained from public sources, and, together with the translation, exchanged between the two parties in plain sight of the adversary. In traditional image steganography, the problem often occurs that the source image in which the message is subsequently hidden must be kept secret by the sender and used only once (as otherwise a “diff” attack would reveal the presence of a hidden message). This burdens the user with creating a new, secret cover for each message.
基于翻译的隐写术没有这个缺点,因为对手无法对翻译应用差异分析来检测隐藏的消息。对手可能会生成原始消息的翻译,但无论使用隐写术,翻译可能会有所不同,使得差异分析无法检测隐藏的消息。
为了证明这一点,我们实现了一个隐写编码器和解码器。该系统通过以类似于在现有 MT 系统中观察到的变化和错误的方式更改机器翻译来隐藏消息。我们的网页上提供了原型的交互式版本。
在本文的其余结构如下。首先,第 2 节回顾了相关工作。在第 3 节中,描述了隐写交换的基本协议。在第 4 节中,我们给出了现有机器翻译系统中产生的错误的特征。第 5 节概述了实现和一些实验结果。在第 6 节中,我们讨论了基本协议的变体,以及各种攻击和可能的防御。
本文的基本隐写协议工作如下。发件人首先需要获得源语言的封面(cover)。封面不必是保密的(secret),可以从公共来源获得 , 例如,新闻网站。然后发送者使用隐写编码器将源文本中的句子翻译成目标语言。隐写编码器本质上为每个句子创建多个翻译,并选择其中之一来对隐藏消息中的位进行编码。然后将翻译后的文本连同足以获得源文本的信息一起发送给接收者。这可以是源文本本身或对源的引用。然后接收者还使用相同的隐写编码器配置执行源文本的翻译。通过比较结果句子,接收者重建隐藏消息的比特流。图 1 说明了基本协议。
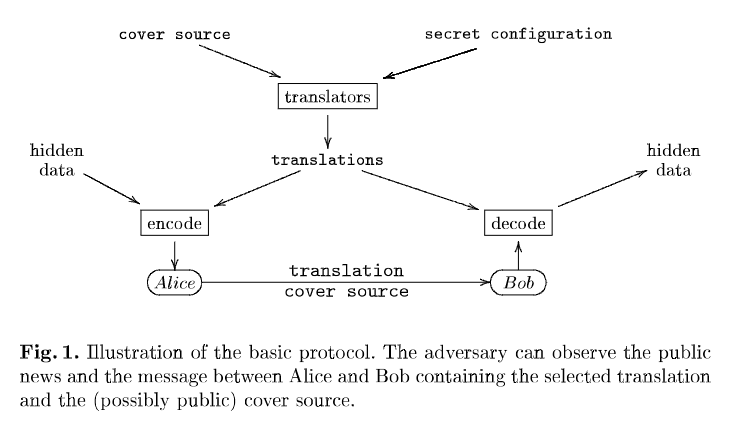
获取源文本后,发送方和接收方的第一步是使用相同的算法生成源文本的多个翻译。此步骤的目标是确定性地生成源文本的多个不同翻译。实现这一目标的最简单方法是在源文本中的每个句子上应用所有可用 MT 系统的(子集)。如果各方可以完全访问统计 MT 系统的代码,他们可以通过使用不同的语料库训练,从同一代码库生成多个 MT 系统。
除了使用多个翻译系统生成不同的句子外,还可以对结果翻译应用后处理以获得额外的变化。这种后处理包括模拟任何(MT)翻译中固有噪声的转换。例如,后处理器可以插入常见的翻译错误(如第 4 节所述)。
由于不同引擎之间的翻译质量不同,并且还取决于应用了哪些后处理器来处理结果,因此翻译系统使用启发式方法为每个翻译分配一个概率,描述其与其他翻译相比的相对质量。启发式可以基于生成器的经验和基于语言模型对句子质量进行排名的算法 。用于生成翻译及其排名的特定翻译引擎、训练语料库和后处理操作集是想要进行秘密通信的两方密钥共享的一部分。
选择翻译以对隐藏消息进行编码时,编码器首先使用生成器算法分配的概率构建可用转换的霍夫曼树。然后算法选择与要编码的位序列对应的句子。
使用霍夫曼树根据翻译质量估计选择句子可确保较少选择翻译质量较低的句子。此外,所选翻译的质量越低,传输的比特数就越高。
这减少了所需的封面文本总量,从而减少了对手可以分析的文本量。编码器可以使用相对翻译质量的下限来排除估计翻译质量低于某个阈值的句子,在这种情况下,该阈值成为发送者和接收者之间共享秘密的一部分。
所提出的方案可以适用于需要对源文本保密的水印。这可以按如下方式实现。编码器计算每个翻译句子的(加密)哈希。然后它选择一个句子,使得翻译句子的散列的最后一位对应于要传输的隐藏消息中的下一位。 然后解码器只计算接收到的句子的散列码并连接相应的最低位获取隐藏信息。
该方案假设句子足够长,几乎总是有足够的变化来获得具有所需最低位的散列。每当没有一个句子产生可接受的哈希码时,就必须使用纠错码来纠正错误。使用这种变化会降低编码所能达到的比特率。更多细节可以在我们的技术报告中找到。
现代 MT 系统会在翻译中产生许多常见错误。本节描述了其中一些错误的特征。虽然我们描述的错误不是可能错误的完整列表,但它们代表了我们在示例翻译中经常观察到的错误类型。翻译错误的扩展特征可以在我们的技术报告中找到(由于篇幅限制,此处省略)。这些错误中的大多数是由于当代 MT 系统对统计和句法文本分析的依赖造成的,导致缺乏语义和上下文意识。这会产生一系列错误类型,我们可以使用它们来合理地改变文本,从而产生进一步的标记可能性。
一类经常发生但不破坏意义的错误是功能词翻译不正确,如冠词、代词和介词。因为这些功能词通常与句子中的另一个词或短语有很强的关联,复杂的结构似乎经常会导致这些词的翻译错误。此外,不同的语言对这些词的处理方式非常不同,因此在使用未考虑这些差异的引擎时会导致翻译错误。
例如,许多使用冠词的语言并不在所有名词前使用它们。这在从文章规则不同的语言翻译时会导致问题。例如,法语句子“La vie est paralysee.”在英语中翻译为“Life is paralyzed.”。然而,翻译引擎可以预见地将其翻译为“The life is paralyzed.”;“life in general”意义上的“life”并没有用出现在一篇英文文章中。这与许多不可数名词如“水”和 “钱”一样,而导致类似的错误。
通常,介词的正确选择完全取决于句子的上下文。例如,法语中的 J′habite à 100 mètres de lui在英语中的意思是“我住在离他100米的地方”。然而,[20] 将其翻译为“我与他一起生活 100 米”,而 [71]将其翻译为“在他的 100 米处生活”。两者都使用“à”(“with/in”)的不同翻译这完全不适合上下文。
不太常见的是,在翻译中选择完全不相关的单词或短语。例如,I’m staying home和I am staying home都被[20]翻译成德语为Ich bleibe Haupt(I’m staying head)而不是Ich bleibe zu Hause。这些不同于语义错误,反映了实际引擎或其字典中的某种缺陷,明显影响了翻译质量。
遇到了其他几种有趣的错误类型,由于篇幅原因,我们将只简要介绍这些错误类型。
类型学上相距遥远的语言是指形式结构彼此完全不同的语言。这些结构差异体现在许多领域(例如句法(短语和句子结构)、语义(含义结构)和形态(词结构))。毫不奇怪,由于这些差异,在类型上相距遥远的语言(中文和英文、英文和阿拉伯文等)之间的翻译经常很糟糕,以至于不连贯或不可读。我们在这项工作中没有考虑这些语言,因为翻译质量通常很差,结果翻译的交换可能是难以置信的。
本节描述了实现的一些方面,重点介绍了用于获得生成的翻译变化的不同技术。
当前实现使用 Internet 上可用的不同翻译服务来获得初始翻译。当前的实现支持三种不同的服务,我们计划在未来添加更多服务。添加新服务只需要编写一个函数,将给定的句子从源语言翻译成目标语言。应使用可用 MT 服务的哪个子集由用户决定,但必须至少选择一个引擎。
选择多个不同翻译引擎的一个可能问题是它们可能具有不同的错误特征(例如,一个引擎可能无法翻译带有缩写的单词)。知道特定机器翻译系统存在此类问题的对手可能会发现所有句子中有一半存在与这些特征匹配的错误。由于普通用户不太可能在不同的翻译引擎之间交替,这将揭示隐藏消息的存在。
更好的选择是使用相同的机器翻译软件,但使用不同的语料库对其进行训练。特定语料库成为隐写编码器使用的密钥的一部分; Victor Raskin 和 Umut Topkara 之前在另一个上下文([2] 的上下文)中讨论了这种使用语料库作为关键字的情况。因此,对手无法再检测到不同机器翻译算法导致的差异。这种方法的一个问题是获得好的语料库很昂贵。此外,划分单个语料库以生成多个较小的语料库将导致更糟糕的翻译,这可能再次导致可疑文本。也就是说,完全控制翻译引擎还可以允许翻译算法本身的微小变化。例如,GIZA++系统提供了多种计算翻译的算法[9]。这些算法的主要区别在于如何生成翻译“候选结果”。更改这些选项也有助于生成多个翻译。
从翻译引擎获得一个或多个翻译后,该工具会使用各种后处理算法生成其他变体。只需使用一个高质量的翻译引擎并依靠后处理生成替代翻译,就可以避免使用多个引擎的问题。
语义替换是一种非常有效的 post-pass,并且已在以前的方法中用于隐藏信息 [2,5]。与以前工作的一个主要区别是,与原始文本中的语义替换相比,由语义替换引起的错误在翻译中更合理。
传统语义替换的一个典型问题是需要替换列表。替换列表是由语义上足够接近的词组成的元组列表,可以在任意句子中用一个词替换另一个词。对于传统的语义替换,这些列表是手工生成的。语义替换列表中的一对单词的示例将是舒适和方便的。不仅手工构建替换列表很乏味,而且列表中包含的内容也必须是保守的。例如,一般替换列表不能包含诸如明亮和光之类的词对,因为光可以用于不同的意义(意味着轻松、不精确甚至用作名词)。
翻译的语义替换没有这个问题。使用原始句子,可以自动生成语义替换,甚至可以包含上述某些情况(无法添加到一般单语替换列表中)。基本思想是在两种语言之间来回翻译以找到语义相似的单词。假设翻译是准确的,源语言中的单词可以帮助提供必要的上下文信息,以限制对当前上下文中语义接近的单词的替换。
假设源语言是德语(d),翻译的目标语言是英语(e)。原始句子包含一个德语单词 d1 并且翻译包含一个单词 e1,它是 d1的翻译。基本算法如下,如图2所示:
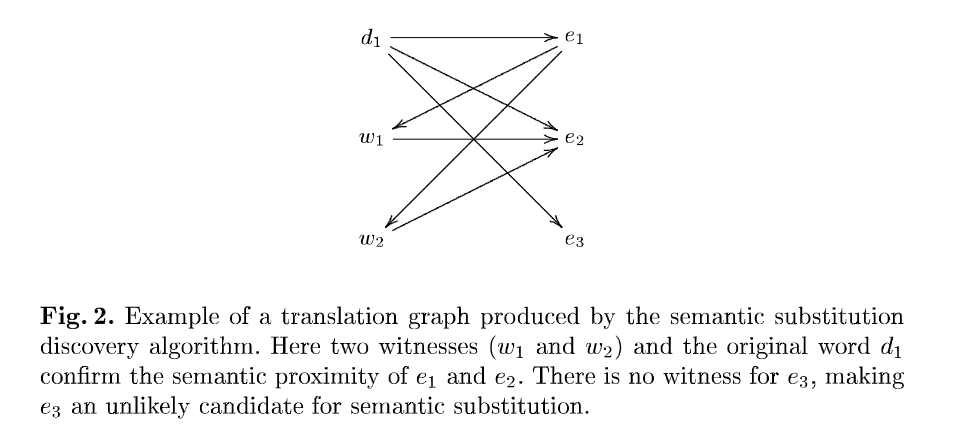
一个witness是源语言中的一个词,它也翻译成目标语言中的两个词,从而确认两个词的语义接近度。witness阈值 t 可用于将更多可能的替换与更高的不适当替换的可能性进行交换。
另一种可能的 post-pass 将 MT 系统常见的错误添加到翻译中。我们的实现可以使用的转换基于第 4 节中对 MT 错误的研究。当前系统支持使用手工制作的语言特定替换来更改冠词和介词,这些替换尝试模仿观察到的可能错误。
系统的不同配置产生不同质量的翻译,但即使质量下降也是不可预测的。有时我们的修改实际上(巧合)提高了翻译质量。
应该注意的是,为简单起见,原型当前使用的引擎是公开可用的免费网络引擎,并且这不是自定义生成引擎或付费商业软件的输出的示范。为了更好地说明原型系统,给出了以下稍微更广泛的示例: 24 位字符串“lit”是在来自 Deutsche Welle 网站的电影评论部分的翻译中编码的。使用我们的原型将文本从德语翻译成英语,没有语义替换,启用冠词和介词替换,也没有“不良阈值”。源引擎是 Babelfish、Google 和 LinguaTec。德语文本是一段关于摩洛哥电影《风马》的评论的第一部分,内容如下:
······省略······
本节讨论对隐写编码的各种攻击以及针对这些攻击的可能防御。讨论是非正式的,因为该系统基于 MT 的缺陷,这些缺陷很难正式分析(这也是 MT 是一个如此困难的话题的原因之一)。
【所提出的隐写编码在未来可能面临的一个可能问题是机器翻译的重大进展。如果机器翻译变得更加准确,那么可能出现的似是而非的错误可能会变得更小。然而,当前机器翻译错误的一大类是由于机器翻译器没有考虑到上下文。】
为了显着改进现有的机器翻译系统,一个必要的功能是保存从一个句子到下一个句子的上下文信息。只有有了这些信息,才有可能消除某些错误。但是将这种上下文引入机器翻译系统也为在翻译中隐藏信息带来了新的机会。【一旦机器翻译软件开始保留上下文,使用隐写协议的两方就有可能使用这个上下文作为密钥。】通过为各自的翻译引擎植入 k 位上下文,他们可以使翻译中的偏差变得合理,迫使对手可能尝试2k种可能的上下文输入,以便甚至确定使用该机制的可能性。这类似于基于密钥拆分语料库的想法,不同之处在于不会影响每句翻译的整体质量。
在翻译中隐藏消息的任何方法的一个普遍问题是,如果源语言中的文本包含两次相同的句子,它可能会被翻译成两个不同的句子,具体取决于隐藏位的值。由于机器翻译系统(不保留上下文)总是会产生相同的句子,这将允许攻击者怀疑使用了隐写术。解决这个问题的方法是不要在源文本中使用重复的句子来隐藏数据,而始终输出用于该句子第一次出现的翻译。
这种攻击类似于图像隐写术中使用的攻击。如果图像经过数字化修改,图像某些不可信区域的颜色变化可能会揭示隐藏信息的存在。解决这个问题对于文本隐写术来说更容易,因为检测两个句子是否相同比检测图像中的一系列像素属于相同的数字构造形状并因此必须具有相同的颜色更容易。
统计攻击在击败图像、音频和视频的隐写术方面非常成功(参见,例如,[8,14,19])。对手可能有一个统计模型(例如语言模型),所有可用 MT 系统的翻译都遵守该模型。例如,Zipf 定律 [15] 指出,一个单词的频率与其在所有单词的按频率排序的列表中的排名成反比。Zipf 定律适用于英语,事实上,甚至在名词、动词、形容词等个别类别中也适用。
假设所有合理的翻译引擎通常都遵循这样的统计模型,隐写编码器必须小心不要导致与此类分布的明显偏差。一旦知道这样的统计规律,实际上很容易修改隐写编码器以消除明显偏离所需分布的翻译。例如,Golle 和 Farahat [10] 指出(在不同的加密上下文中)可以在不明显偏离 Zipf 定律的情况下广泛修改自然语言文本。换句话说,这是一个非常易于管理的困难,只要隐写系统是“Zipf-aware”的。
我们不能排除尚未发现的翻译语言模型的存在,这些模型可能会被我们现有的实现所违反。然而,我们希望发现和验证这样的模型对于对手来说是一项重要的任务。另一方面,给定这样的模型(正如我们上面指出的)修改隐写系统很容易,通过避免被标记的句子来消除偏差。
Adjective Deletion for Linguistic Steganography and Secret Sharing
概念
Adjective Deletion 【形容词删除】
Linguistic Steganography 【语言隐写术】隐写术就是将秘密信息隐藏到看上去普通的信息中进行传送。
Linguistic steganography is a form of covert communication in which information is embedded in a seemly innocent cover text so that the presence of the information is imperceptible to an outside observer (human or computer).
理想的 Linguistic Steganography满足两个基本要求:high imperceptibility(不易察觉) and high payload capacity(高信息承载容量)
Secret Sharing 【密钥共享】一种分发、保存、恢复秘密密钥的方法。
文章所作工作
验证删除形容词的可行性的两种方法:「checking the acceptability of adjective deletion in noun phrases.」
证明删除形容词技术可以集成到一个存在的语言系统(an existing linguistic stegosyste)
提出一种新的基于形容词删除技术(adjective deletion)的密钥共享(secret sharing)方法
(t,n)-threshold scheme
论文中采用的 secret sharing方法是基于(2, 2)-threshold, 其中共享的必须是两个可比较的文本(two comparable texts)。通过形容词删除技术将【0s 和 1s 的加密位字符串(secret bitstring;)】嵌入到两个文本中,这两个文本可以组合起来,获得秘密位串。
Hence the proposed method is a novel combination of secret sharing and linguistic steganography.
一种密钥共享与语言隐写技术的新颖组合方法?!
Adjective Deletion
在不影响句子流利程度和语义的情况下,可以将一些形容词删除。在下面的例子中,删除 own 这个形容词后,句意并没有发生改变。
he spent only his own money.
he spent only his money.
一种极端情况 adjective-noun :大致可以理解为正确的废话(正确但duck不必的形容)吧。
unfair prejudice
horrible crime
fragile glass
隐写术种的语言转换(Linguistic Transformations for Steganography)
如:词汇替换、短语意译、句子结构调整、语义转换等【PS:有种毕业论文降重的赶脚】
还有一种研究通过在翻译的文本中嵌入信息。在机器翻译算法中引入水印作为参数,对带有水印的译文进行概率识别。
【Watermarking the outputs of structured prediction with an application in statistical machine translation】
Another recent work proposedby Venugopal et al. (2011) introduces a watermark as a parameter in the machine translation algorithm and probabilistically identifies the watermarked translation.
隐写系统评估
可以从两个方面对系统进行评估:安全性(security level)和嵌入容量( embedding capacity)
security level: automatic evaluation and human evaluation.
automatic evaluation 大概就是使用机器翻译评价指标 BLEU 和 NIST。计算隐藏文本与原始文本之间的距离。
human evaluation 就是认为指定的一套评估标准(seven-point scale)。
embedding capacity
将嵌入的信息按每个语言单位(每个句子或每个单词)比特进行量化。
隐写系统的语言转换和编码方法,以及隐写文本的选择都会影响隐写系统的安全级别和有效负载能力。
句子压缩
句子压缩,文本简化和文本摘要通常涉及删除句子中不重要的词,以使文本更简洁。论文中指出,形容词删除可以用在句子压缩之前或之后。进一步简化句子。
The proposed adjective deletion methods can be applied before and/or after a sentence compression system. Deleting unnecessary adjectives before can help the system focus on other content of a sentence. Deleting unnecessary adjectives after can generate an even more concise sentence.
Deletable Adjective Classification
论文中,为了使一个形容词的删除是可以接受的,使用两个检查:语法性和自然性检查(grammaticality and naturalness checks)。
计算删除形容词前后文本的 N-gram 统计得分,通过设置一个阈值,来判断删除后的文本是否可接受。
支持向量机的特征有:
Secret Sharing Scheme
将一个密钥位串分成两个部分share0和 share1 。若目标形容词在share0 中保留,则密钥值取0,若目标形容词在share1中保留,则密钥值取1。
Share0 holds secret bits as 0s and Share1 holds secret bits as 1s
下面是一个密钥位串为 101 的例子:

赛题:蛋白质结构预测挑战赛
代码:
1 | ################## utils.py ##################### |
提交结果:目前【14/27(提交团队数)】

主要是提取了氨基酸组成(AAC)特征,即一些简单的统计特征。没有考虑氨基酸之间的相对位置信息,也没有必要调参,最后预测结果也很是拉跨。
下一步直接尝试nlp 相关模型。
前言
这里收纳遇到的一些Problem
,包含一些生活中遇到的人或事。是泛指,而绝不是某类问题。想法来源于SCP
基金会,也和一首歌有关《瓶与抛光者》。而起因却是迪迦与伍六七的下架。
我感觉我们正失去一些美好的东西,善良、温柔、体贴,这些属于我们人类美好的本质,好像正慢慢淡化!— 新城
不拼尽全力试一下又怎么会知道啊! —阿七
随着时间推移,愈发感觉对于很多事情都很无力。被矫枉过正的灵魂,嘴硬蛮横。
没有那么果敢(三思而后行/胆怯),没有那么坦诚(冷暖自知/尔虞我诈)、没有那么期待(活在当下/躺平)……然后成熟稳重。
要藏起一些光芒(谦逊/自卑),收敛一些个性(低调/普通),寻找一些共性(合群/跟风)……然后求同存异。
大道理听了很多,依旧过不好。可总是有人唠叨,也总是有人听。以至于我们活的越来越像别人……
当大人不在苦口婆心耐心教导小孩明辨是非时,他们开始试图将自认为不适合小孩的东西封杀雪藏。可谓另辟蹊径,偷教育的懒。似乎想达到同步教育 的目的。
同步教育: 并不是所有家长都能管好自家小孩,譬如打游戏,看电视。于是举报游戏,举报动画片,以此达到所有小孩都玩不了游戏,看不了动画片的目的,这样看似省心省事。
几十载的一生,活着的意义又是什么呢。以前什么都不懂,过一天是一天,现在懂的多了,过一天算一天,还要总结昨天,规划明天,才能过好今天。
夜深人静,当我们思考这一天,或最近的状况时,都企图得出一些人生大道理,悟出生活中的真谛,寻求内心的平静。自己到底是一个什么样的人?对于这个问题,好像每天都有不同的答案。
于是在百无聊赖的生活里,寻找明天继续的理由……
最后感恩!迪迦又上架了。
Problem Container
将作为理由之一,在互联网的大海里漂流。以下是收容的一些Problem
。
布丁
——2020.8.21 ——
布丁是妹妹过年时带回家的宠物狗。全身白色,眼睛很大,个子却很小,年龄有一年多了吧。听说是花五十块买的。
记得刚到家时,它很是胆小,只敢跟在妹妹脚边转悠。布丁这个名字只有我妹妹叫,才有用,其他人不行。后来慢慢熟悉了,它也开始放的开了。每天都会发疯一样来回窜。布丁好像对一切充满了好奇,能吃的,都要尝一尝,以至于给它的狗粮,成了它最不济的选择。
家里有只猫,布丁很怕猫,每次布丁想去接近猫的时候,猫都会用爪子示意。猫有时会去偷吃狗粮,布丁看见了,只能在旁边看着干着急,然后发出委屈的声音。有次它跑过来挠我的脚,示意我把猫弄走。我把猫赶走后,布丁就开始吃狗粮了。虽然,它不喜欢吃狗粮,但也不许别人动它的东西。
妹妹回深圳上班了,特殊时期,只能把狗留在家里了。那天晚上布丁没有见到妹妹,它就在妹妹房间门口等,眼睛泪汪汪的,身体蜷缩着,压在妹妹的拖鞋上面。我打开房间门,布丁立马起身跑进去,然后扒拉床沿,看妹妹在不在上面。确认没有后,它失望地走了出来。
从此,布丁就交给我了。每天早上布丁会早早地起来扒拉床沿,把我弄醒,示意我开门下楼放它出去上厕所。刚开始,看着它越走越远时,还是有些担心的,怕它不知道回来。庆幸的是,每次在我焦急等着喊它名字的时候,它都兴冲冲地跑回来了。
布丁好像很孤独。那段时间,明天都上网课,然后它就趴在地上,在旁边陪着我。久而久之,布丁已经摸清我的习惯了。什么时候下课,什么时候吃饭,什么时候睡觉,什么时候在房间里。我也知道每天早上七点下楼开门放它出去玩半个小时,然后回来陪我上网课,中午大概十二点和我一起下楼去吃午饭,吃完后,我会先上楼,布丁会在一点多的时候,上楼来挠我房间门,示意我开门。开门后,布丁会先喝水,然后走到窝里睡午觉。布丁晚上睡觉很早,但是我每天都会熬到十二点多才睡,开着灯,有些影响它。它的耳朵很灵,晚上我关灯躺床上刷手机,一点点声音,它就会过来床边,两只爪子扒在床上,然后抓蚊帐,示意我关掉。有段时间,它可以和周边其它狗打成一片了,甚至成了团宠。我感到有些欣慰,但也有些忧虑。其他狗都是散养的,乡下那种土狗。布丁是个娇生惯养的宠物狗,和土狗打成一片,不可避免要惹上一些虫子。每天给布丁洗澡,成了我每天最烦恼的事情。有那么几次,被朋友约出去玩。上午出门,傍晚才回家。每次回家刚把钥匙插进去,布丁就知道我回来了,马上从楼上跑下来,汪汪地叫着。我一进去,布丁就开始扒拉我的脚,时不时发出一种憋屈地要哭了的声音。看得出,布丁在用尽它所有的动作或表情来欢迎我。它大概是以为我不回来了,把它抛弃了吧。
布丁是会哭的。妹妹回来过一次,布丁开心得活蹦乱跳的,两只小脚不停的扑妹妹。好像在倾其所有表达它有多爱妹妹。妹妹没让布丁去她房间里,依旧把它留在我房间。布丁不停的用爪子挠门,想要出去,进妹妹房间。见我不开门,布丁开始急了,扑我身上,用一只小爪子挠我,发出委屈的声音,两眼泪汪汪的,眼泪都出来了。我开门后,它又不停的去挠妹妹房间的门。最后累了就躺在妹妹拖鞋上面,蜷缩着身子,等着。
几个月的时光,就这样患得患失地过来了。很快到了返校时间。一大早就急匆匆的离开了,布丁应该以为我会像以前一样,到了晚上就会回来吧。它大概在楼上阳台观望,等待,直到夜幕降临。
陪我半年的布丁,无疑是我这半年来最大的收获。朝夕相处的那段时光,算是我最开心的时候吧。
前言
第一次参加cv
赛事,由清华举办的一场AI 挑战赛 , 旨在推广
jittor框架的吧。传送门
共有两个赛道,一个细分类,一个目标检测。由于有一个毕设与目标检测相关,于是毫不犹豫的报名参加了。算是入坑DL
了。前期在tensorflow 、pytorch
、jittor
三大框架之间反复横跳,最后还是抛弃了tf。主要是服务器上的tf用不了显卡的算力。环境问题懒得去倒腾了。pytorch
上手也很快,而且与jittor 相似。
选着狗细分类这个赛道试水,结果差点每淹死在水里面。查阅了许多细分类的论文,一个个提到说效果达到SOTA
,结果到自己手里就废了。
在好的配方,也能被炼废。
拿到配方,丹炉架好,药材就绪,大力按下回车键后,看着进度条缓缓加载,epoch 1,2,3,…
这是一个漫长的过程,睡一觉第二天醒来,观察各项指标变化,没有预期那么好,却也差强人意。点击提交后,果然,依旧没有好的效果。2021.2.19,在尝试好几种配方,反复炼丹数十余日后,最终还是以失败告终。
高端的食材往往只需要简单的烹饪。
按照
baseline的方法,仅仅只是使用了一个简单的resnet50分类网络而已,最后的效果却要高于我各种花里胡哨的方法好几个百分点。开源的基线已是我望尘莫及的极限了。着实有些颓废。
I know nothing but my ignorance.
炼丹之路注定是布满荆棘的坎坷之路。才疏学浅,当厚积薄发才是。
说来搞笑,翻看去年的记录这样写道:
2020.12.31 总结
想总结来着,但仔细一想,实在不知道如何说起。那就祝自己少活几十年吧,哈哈哈哈哈。
2020我记录了很多天发生的事情。在入睡前,回想一下近况如何。
关于过年,除夕夜自己一个人在房间里敲着代码,跑着深度学习的第一个demo,想来马上就是自己入坑深度学习一年了。第二天春节,和往常一样待在房间里追剧、打游戏、敲代码。好像和平常没什么两样。我会说:当我不去在乎节日里的仪式感,节日也就是平常,我也就把每天都当作节日一样过着了。春节快乐!
2020.2.15,有关考研,自己也很纠结。可能是对自己实力的不自信,也可能是对自己本科四年的失望吧。细想过去的三年,无非在应付无关紧要的作业,参加可有可无的活动,平衡泛泛之交的同学关系,权衡尔虞我诈中的利弊。很是失败,也很无奈。我说:我在百无聊赖的生活里,寻找明天继续的理由……
关于五一,记得前一天四月三十号,组建了第一个大数据比赛队伍,队伍名字就叫430。这一天回想了过去几个月的状态。本以为2020年是个好兆头,会是一个对我来说,重新开始的一年。我以为所有的不快、压抑、不良情绪都抛在了2019年。可是并没什么改变,我发现我依然无法和过去和解,尽管我几乎不记得发生了什么。当我开始搜索抑郁症相关信息时,我发现自己的状况好像并没有那么乐观。我无法确定,自己在互联网里寻找到的蛛丝马迹是为了得到什么样的答案。如果有一天,自己去医院就诊,然后被医生判定重度抑郁时,我大概在想:是我把医生骗了,还是医生在骗我。总之花了不少钱。我会说:我无数次把房间门反锁,这个时候,我总觉得我还算快乐……
2020.6.23,记录中这是熬夜的一天,月初开始的大数据挑战赛初赛即将结束,月初开始的专业综合实训也接近尾声。昨天开始写实训报告,在今天凌晨三点左右凑够了9000+字数。睡一觉接着补15天的实训日记,第一次觉得200字的日记也是真的难写。BDC初赛结束也只有四天了,每天看着榜单上的名次往下掉,自己却一点法子都没有。询问老师,得到的回复总是“你用的什么模型”,或者抛来几个博文链接给我。值得庆幸的是目前还没有掉出榜单前100,还是有一丝机会的。最后几天还能挣扎一下。我会说:所有不能打败你的,都将使你变得更强……
2020.7.20,这一天是和自己谈判的一天。逃离家庭,却终将要与自己和解。和平相处,peace and love……。这天我会说:最后这故里我想我是不会回来的……
2020.7.30,靠着一点运气,以51的名次苟进了复赛。新建无数次的notebook,处理了无数次的数据、尝试了各种模型,效果依旧不如人意。最后的nn模型是我最后的倔强了,经过接近十个小时的模型训练,最终以收敛失败告终。我开始思考,自己这十几天的思路与付出是否真的是错的。思索良久,决定重新开始。重新清洗数据,重新做特征工程……我安慰自己:不是所有努力都会有回报,最终收不收敛,还得看你努力的方向是否正确……
2020.8.10,比赛截至,苟进复赛,止步于此,34名。算是满意吧。从六月初到现在也熬过两个月了。期间有过很多次想过放弃,一方面指导老师没怎么指导,另一方面自己还是个入门两三个月的机器学习练习生而已。但是不知道为什么,还是抱着忍一忍的心态,挺了过去。算是在老师那刷刷存在感吧,毕竟考研可能要报他那。漫长黑夜,对着电脑,笨拙的手指在黑白机械键盘上敲出清脆的声音,这是我喜欢的音乐,这是我喜欢的世界。我会想:所有的坚持,都会是为未来埋下来的伏笔吧……
2020.8.15,这天生日,已然苟活整整21年。几十载的一生,活着的意义又是什么呢。小时候什么都不懂,过一天是一天,现在懂得多了,过一天算一天,还要总结昨天、规划明天,才能过好今天。一个普通人的一生该是什么样的?二十到三十,这十年该如何度过,我也只能走一步看一步了。我很庄严的告诉自己:管他三七二十一,先做自己想做的事,说自己想说的话,走自己想走的路……
2020.8.21,这天是回学校的日子。记录了我和布丁相处的半年多的时间的一些事情。它大概以为我会晚上到点就回来,但是这次真的好久都不会回来了。若是重来,我想对它说:你好,布丁,招待不周,还望见谅。
2020.9.26,很多事都不一样了,在表示同意赞赏nb还行的同时,其实内心也在保持着一些最后的倔强甚至不屑的态度。向往诗和远方的同时,也在吐槽当下糟糕的境况。这是暂时的妥协,而不是最后的结果。可以预见的是,有一天,我也会被一块大饼圈住,为别人给的蛋糕沾沾自喜,因为天上掉的馅饼开始信奉神明,在推杯换盏中周旋,吃饱了面包然后驻足休息,养老等死,我的墓志铭大概就是我的第一个”hello world”代码。这是我最后的倔强,而不是暂时的妥协。技术无罪,资本作祟的时代,人人都好像鬼怪,争夺面包,吸食人xie,手捧圣经,说着抱歉,最后还不忘总结,口感似乎差了点……
2020.10.4,国庆假期,这天我在学校。记录里这样写着:不可否认的是,大学里,我尝试过很多方法去改变我那自卑内敛的性格。参加社团,参加义务家教,学着别人的口吻说话,练习不让人讨厌的微笑……努力让自己看起来有些自信。十八九岁总带有一些理想的冲动,二十几岁了相对来说多了些理性的思考和对未知的焦虑。不可否认的是,很多很多困扰我的问题,对于上大学的我,依旧难以给出理智的回答。就连一日三餐吃什么,都要犹豫半天。我会说:大道理听了很多,依旧过不好。可总是有人唠叨,也总是有人听。以至于我们活的越来越像别人……
2020.10.5,长沙13℃,风很大。去图书馆的路上,遍地桂花。一场雨,一阵风,桂花落,好像宣告秋天结束,冬天来了。然而现在才10月份开头。到图书馆已经是八点半了,进自习室,发现差不多坐满了,剩下些零零散散的位置。索性经常坐的位置没有人占。平常一般六点半起床,大概七点半到。最近放假,放松了几天,生物钟还在慢慢调回去。十一点多已经快饿得不行了。早上买的肉夹馍和豆浆,只是吃了几口就扔了。找到适合我的早餐或许到毕业都不太可能吧。自己已经感觉到明显的头晕想睡觉,之前一直以为是休息不好,直到最近才意识到自己这是低血糖的症状。食堂只开张了寥寥几家店,但是留校的人却很多。选择了一家人少的馄饨面。结果忘记叫他不要放葱了。打包回寝室,边看剧边挑着馄饨面里的葱。又是一个多小时的午餐。寝室睡一觉,接着去图书馆学习。拿出历年英语真题开始做阅读理解,到目前为止,正确率依旧只有百分之五十左右。很是崩溃,单词记得也不多。做完已经快五点,好像又开始低血糖了。于是玩了一下手机。五点过后开始收拾东西走了。晚饭去西门吃了,顺便剪个头发。接着逛超市,买了一些零食和糖果。晚上睡觉前,有关智齿的问题纠结了我大半个小时,第一次长,害怕拔牙的痛苦。逮到人就问长了智齿没有。这颗智齿好像是最近开始长的,没有多大。算是给我这平平淡淡的生活徒增了一些烦恼,又或者埋下了一个小小的伏笔……智齿好像每个人都会长,但不是每个人都需要拔,除非它发炎。所以真特么刺激,这可爱的智齿……
2020.10.7,憨憨从望城那边赶了回来。一进寝室就说快祝我回归单身。于是开始聊了起来。他说其实分开很久了,九月份的时候就分了。什么原因,他说很复杂。现在他们唯一的共同财产就是那条狗了。反正我是不太相信的,坐等他们复合请吃饭吧。如果他们都走不到最后,那我觉得所谓爱情也不过如此了。二十几岁的我,现在也没有特别想谈恋爱的冲动。现在的我,还有很多问题无法回答,很现实,也很必要。我常常想:我们好像都在换位思考,理智分析各自的问题,却依旧无法做出满意的决定……
2020.10.11,这一天有感而发,层出不穷的社会丑闻,每天都在发生。在事情没有结果的时候,就已经有人抢占道德高地,开始火力全开,声张自己的正义,字里行间表达的都是我是对的。舆论一边倒,好像已经板上钉钉了。当结果出乎意料时,所有人惊呼人心叵测,却少有人思考其中的前因后果。我们只在乎吃瓜时的快感,那股正义凛然的劲。指尖在键盘上轻轻舞动,就能让互联网的另一头引发轩然大波。我明白:人言可畏,在互联网中,表现的如此淋漓尽致。
2020.10.14,最近被大连理工研究生自杀的新闻刷屏了。是啊,好好的一个人怎么就这样了。作为一名大四考研生,看到这个新闻时,第一想到的不是自己研究生的情况怎么样,而是在想,一个平常看起来挺正常的人,到底积攒了多少的糟糕的心情,才突然爆发了呢。有时候我也会觉得自己就是那样的人,对于很多事无奈的时候,就干脆做一个别人眼中认为的那个人。在不同角色之间来回切换,如同推杯换盏中达成一致。我说:在平衡内心与周遭的过程中,缝缝补补自己眼中那千疮百孔的世界……
2020.10.15,记录着这样一段话:寻求一些期许,满足对未来的幻想,提醒今天的自己,你要加油啊,社畜……
2020.10.18,早早洗完澡,就躺床上去了。刷着手机,思绪突然凌乱。胡思乱想中,脑海里浮现了布丁的身影。我无法想象在未来某一天,布丁生命终结,我该如何面对。这是我一开始就害怕面对的问题。与它待的每一天,我好像都会害怕眼前美妙的情景在未来哪天突然消失。我不擅长面对这样的场面,我应该也很很难走出来。至少生命中,某些时刻,会时不时浮现脑海里,就像现在这样。有些珍贵的情感,不需要触景而生,就在生活中的某些时刻突然想起,无需刻意回忆。
2020.10.19,这一天记录了一篇小说偷影子的人。这是一部小说,以童年的故事作为铺垫,以成人后的追忆把小说推向高潮。小说不长,却很抓人。小说里那种细腻的感触,总是不经意间出现。我们自以为忘记了过去,但生活自会把我们引进回忆,然后拾起一段又一段珍贵的情感……“随着时间的流逝,有些事自会迎刃而解。”,“你偷走了我的影子,不论你在哪里,我都会一直想着你。”最近总是半夜醒来,说不清楚什么原因。可能是睡得早了,可能是做了噩梦。近来确实容易做梦,梦见布丁去世,梦见与爸妈吵架,梦见一些生活的一些事的后续,事情发展越发荒唐……我开始害怕自己的影子被别人偷走,我不太能确定它是否可靠,是不是轻易就能说出我不愿说的心事。我不相信我的影子。我不太愿意回忆过去了,甚至开始选择性的去忘记一些事情。我希望一切往前看,即使过去一团糟,我依旧觉得明天是我可以逃避一些事的地方,在那里前途一片光明。不问过去:我尽量准备好明天的到来,尽管今天过得并不怎么样……
2020.10.25,这一天的标题是寻人启事。考研让我的生活变得规律起来。早上六点半起床,七点吃早饭,七点半到图书馆学习,然后十一点吃午饭,十一点半回寝室睡觉,十二点半返回图书馆学习,然后直到下午五点,吃完晚饭大概六点,接着学到九点多,然后回寝室洗澡洗衣服刷牙,最后睡觉。在路上常常有种行尸走肉般的感觉,机械的,按部就班的,过着每一天。这样也挺好,忙起来,把生活填满,就不必去思考其他的东西了。可又好像不是这样,我考虑半天三餐吃什么,我可能会思考吃哪一家的,我会计较哪家喜欢放葱,我会犹豫半天吃饭还是吃粉,炒饭还是炒粉,明天什么天气,是否有雨,温度多高,要复习什么内容……我每天都在纠结着这些好像微不足道的小事。夜深了,躺在床上,打着字,思考这一天,或最近的状况。企图得出一些人生大道理,悟出生活中的真谛,寻求内心的平静。自己到底是一个什么样的人?对于这个问题,好像每天都有不同的答案。我想写一份寻人启事,寻找真正的自己……
往后的时间,在刷卷子中度过。自习室里,笔在一张张A3纸上沙沙作响,垫在桌子上的纸一张一张的叠着,慢慢的,越铺越厚。考完那天,回到自习室,抽出那一摞纸张,然后重重地扔进了垃圾堆里,宣告结束了。2020年也结束了。
2021了啊!
2021.1.10,记录了一次失眠。今晚又失眠了。莫名其妙的情绪低落,时不时流眼泪。明明睡前还有说有笑的啊。真是奇怪。不知道从什么时候开始,我好像更希望有个认识的能够说得上话的人在旁边。算了,写不下去了,找个时间看医生吧。受够了……
后来没有去看医生,好像也还能够忍受。
开学准备复试。。。